NumPy Fundamentals for Data Science and Machine Learning
Note: If you prefer to read with a white background and black font, you can see this article in GitHub here. Las time I check SVG images rendered just fine.
It is no exaggeration to say that NumPy is at the core of the entire scientific computing Python ecosystem, both as a standalone package for numerical computation and as the engine behind most data science packages.
In this document, I review NumPy main components and functionality, with attention to the needs of Data Science and Machine Learning practitioners, and people who aspire to become a data professional. My only assumption is that you have basic familiarity with Python, things like variables, lists, tuples, and loops. Advance Python concepts like Object Oriented Programming are not touched at all.
The resources I used to build this tutorial are three:
NumPydocumentation- A few miscellaneous articles from the Internet
- My own experience with
NumPy
Content-wise, I’ll say that ~95% is based on NumPy v1.18 manual, in particular:
The rest ~5% comes from a couple of random articles on the Internet and Stack Overflow. I resort to those sources mostly to clarify concepts and functionality that wasn’t clear for me from NumPy documentation.
My own experience was the base to organize the tutorial, explain concepts, create practical examples, create images, etc.
“Why are you using the documentation as the main source of content, instead of the many great tutorials online?” Because it is the most up-to-date, complete, and reliable source about NumPy (and about any library for that matter).
“Why then I should read this if everything comes from the documentation?” Well, you don’t need to read this, you are right. Actually, I encourage you to read the documentation and learn from there. What I can offer is my own: (1) organization of contents, (2) selection of contents, (3) explanations and framing of concepts, (4) images, (5) practical examples, (6) and general perspective.
This tutorial is part of a larger project I am working on, which is an introduction to Python and its libraries for scientific computing, data science, and machine learning that you can find here.
If you want to interact with this Notebook, you can open a MyBinder interactive instance by clicking in the MyBinder icon:
To open MyBinder -> ![]()
As a final note, if you are NumPy expert, advanced user, or developer, you may find some inaccuracies or lack of depth in some of my explanations. Two things: (1) feel free to suggest a better explanation or something that I may add to make things clearer, (2) I prioritize conciseness and accessibility over the accuracy, so the lack of accuracy or depth sometimes it is intentional from my part.
If you have any questions or suggestion feel free to reach me out to at pcaceres@wisc.edu Here is my Twitter, LinkedIn, and personal site.
Table of contents
- Python is slow
- What is NumPy
- Installing NumPy
- NumPy Arrays
- Array creation
- Vectorization
- Array data type and conversions
- Array mathematics and element-wise operations
- Array data type and conversions
- Array manipulation
- Logic functions and array evaluation
- Array Indexing
- Array iteration
- Array shallow and deep copies
- Structured arrays
- Random number generation and sampling with NumPy
- Basic statistics with NumPy
- Basic linear algebra with NumPy
- String operations with NumPy
Python is slow
Scientific and numerical computing often requires processing massive datasets with complex algorithms. If you are a scientist or data professional, you want a programming language than can process data FAST. The closer a programming language is to machine instructions (binary), the faster it runs. That’s why for decades, programming languages like C, C++, and Fortran, were the to-go option for data-intensive applications in science and technology.
However, writing code in compiled languages like C++ and Fortran can be slow and, frankly, terribly annoying (but that’s just me!). Scientists are not coders (although many end up mutating into scientist-coder hybrids over time, that’s a whole other subject). From a scientist’s perspective, the easier and faster to write code, the better. High-level programming languages, i.e., languages that are closer to human language rather than to machine language do meet such requirements. The likes of Python, PHP, JavaScript, and Ruby, fits the bill: easy to write, easy to learn, easy to run. But, instructions written in high-level programming languages are slow to run by computers, for complicated reasons I do not explore here. The fact is that they are slower to run than C++ or Fortran.
Scientists face a conundrum: they need an easy to write AND fast to run programming language. They need the best of both worlds. For a long time, such language simply did not exist. Then Python came along.
Oh wait, Python it is, indeed, easy to learn and write, but slow to run compared to compiled languages. Like really, really slow. For instance, computing the spectral-norm of a matrix, which is a common task in data applications, has been benchmarked at ~1.9 seconds in C, whereas python takes a whopping ~170.1 seconds, meaning that Python is ~90 times slower. Considering this, the fact Python became the dominant language in machine learning and data science is a bit of a puzzle.
There are at least two reasons for this why Python succeed anyways.
The first is that as computing capacity became cheaper, processing time has become less important than coding-time. Basically, the time you save by writing code in high-level yet slow to-run programming languages compensates by their lack of performance at run time. And Python is exceptionally clean, intuitive, and easy to learn, compared to C or Fortran.
The second reason, which is probably the major one, is libraries. Particularly libraries written in low-level high-performant languages. Turns out that Python extensibility allows programmers to write the “engine” for numerical computation in languages like C and Fortran, and then Python can invoke such “engines” in the background, meaning that although you write code in Python, it is executed in compiled C or Fortran code instead of Python itself. And that is how you obtain the best of both worlds: the easy and fast developing time of Python, plus the runtime performance of C or Fortran. True, there is some small overhead of going back and forth between languages, but its impact it’s minimal.
It is important to mention that nowadays, new programming languages have been created exactly with these two necessities (fast development + fast performance) in mind, like Julia. In the spectral-norm test, Julia was benchmarked at ~2.79 seconds, almost as fast as C. Additionally, Julia is a dynamic language, easy to learn, and write in like Python. Why not Julia then? Probably because of the relative immaturity of its packages ecosystem compared to Python. Julia first appeared in 2012, whereas Python was introduced in 1990. The availability of well-tested libraries for pretty much anything you can imagine in Python is unparalleled. A second reason is probably that Python does not cost you performance anyways (with its libraries), so Why not?
What is NumPy
It is no exaggeration to say that NumPy is at the core of the entire scientific computing Python ecosystem, both as a standalone package for numerical computation and as the engine behind most data science packages.
NumPy is a package for array-like or matrix-like high-performance computation. Its “engine” is written in C, meaning that NumPy utilized “in the background” pre-compiled C code to perform computations.
Installing NumPy
If you are running this Notebook in MyBinder or locally after running the pip install -r requirements.txt file, you have NumPy installed already. Otherwise, you will need to install NumPy with one of these options:
- Scientific Python Distributions
- pip
- System-wide installation via a package manager (apt, brew, etc.)
- From NumPy source code
Option 4 is for developers who need to alter source code. Option 3 is not recommended as a system-wide installation of packages may generate dependency conflicts.
Option 1 is probably the simplest and it’s widely used by practitioners. Within this category we have:
WinPython and Pyzo are less used and I do not have any experience with them. Feel free to experiment with them at your own risk. Anaconda and mini-conda are the most popular options. Anaconda basically is a large bundle of packages for Python and R, and a package manager. Mini-conda is a lightweight version of Anaconda. Once you install Anaconda or mini-conda, NumPy will be available within the conda installation.
I do not like and do not use Anaconda or mini-conda. I just see no reason to install hundreds of libraries I most likely never use. I also see no reason to duplicate functionality which is already provided in the standard Python installation. It just occupies memory and you also need to learn how to use conda, which sometimes introduces hard to understand issues with multiple Python and packages installations. Yet, many people recommend and use this method. If you decide to use it, go to the Anaconda or Mini-conda site and follow the instructions for your system.
My preferred method is pip, which is available out-of-the-box with your Python installation. To install NumPy is as simple as to run:
pip3 install numpy
Now, I highly recommend to create a virtual environment, activate the environment, and then install NumPy within that. It boils down to copy-pasting the following in your terminal:
# create the virtual environment
python3 -m venv venv
# activate the virtual environment
source venv/bin/activate
# upgrade pip package manager
pip3 install --upgrade pip
#install numpy
pip3 install numpy
The virtual environment will isolate your NumPy installation from your system-wide Python installation and other projects you may have in your computer. So, it’s safer. This method will save you gigabytes of memory, time, confusion, and effort. But that’s just me!
NumPy arrays
NumPy fundamental object is the ndarray. Arrays are simply ordered collections of elements, like single numbers, lists, sets, vectors, matrices, or tensors. In Additionally, elements in an array have of the same type. For instance, an array can’t have integers and text at the same time. The reason is simple: mathematical operations with objects containing multiple data types would be slow, and NumPy main goal is fast and efficient numerical computation.
The “n” in “ndarray” makes references to the arbitrary number of dimensions it can take. An array with one element and one dimension, it’s a “singleton” or just a number. An array with four elements and two dimensions is a 2x2 matrix. Put simply, an array is like an Excel sheet with the caveat that instead of being restricted to two dimensions, it can be extended to 3, 4, or higher dimensions, and that you can’t combine data types in a “sheet”.
In NumPy, dimensions are called axes, so I will use such term interchangeably with dimensions from now.
Let’s see a few examples.
We first need to import NumPy by running:
import numpy as np
Then we can use the array method constructor to build an array as:
# 1 axis/dimensions array
one_dim= np.array([1, 2, 3])
# 2 axis/dimensions array
two_dim_1= np.array([[1, 2, 3]])
# 2 axis/dimensions array
two_dim_2= np.array([[1, 2, 3],
[4, 5, 6]])
# 3 axis/dimensions array
three_dim = np.array([[[1, 2, 3],
[4, 5, 6]],
[[1, 2, 3],
[4, 5, 6]]])
Visually, we can represent the above arrays as:

This is how arrays look when printed:
print(f'One-dimensional array with 3 elements:\n{one_dim}\n')
print(f'Two-dimensional array with 1 row and 3 cols:\n{two_dim_1}\n')
print(f'Two-dimensional array with 2 row and 3 cols:\n{two_dim_2}\n')
print(f'Three-dimensional array:\n{three_dim}')
One-dimensional array with 3 elements:
[1 2 3]
Two-dimensional array with 1 row and 3 cols:
[[1 2 3]]
Two-dimensional array with 2 row and 3 cols:
[[1 2 3]
[4 5 6]]
Three-dimensional array:
[[[1 2 3]
[4 5 6]]
[[1 2 3]
[4 5 6]]]
We can inspect and confirm dimensionality as:
print(f'Number of dimensions array one: {one_dim.ndim}')
print(f'Number of dimensions array two-1: {two_dim_1.ndim}')
print(f'Number of dimensions array two-2: {two_dim_2.ndim}')
print(f'Number of dimensions array three: {three_dim.ndim}')
Number of dimensions array one: 1
Number of dimensions array two-1: 2
Number of dimensions array two-2: 2
Number of dimensions array three: 3
The shape of an array must not be confused with its dimensionality, as shape reflects the number of elements along each axis, and dimensionality only the number of axes or dimensions.
print(f'Shape array one: {one_dim.shape}')
print(f'Shape array two-1: {two_dim_1.shape}')
print(f'Shape array two-2: {two_dim_2.shape}')
print(f'Shape array three: {three_dim.shape}')
Shape array one: (3,)
Shape array two-1: (1, 3)
Shape array two-2: (2, 3)
Shape array three: (2, 2, 3)
The first number in the parenthesis represents the number of elements within the first axis/dimension; the second number the number of elements within the second axis/dimension, the third number the number of elements within the third axis/dimensions, and so on.
For instance, the (2, 2, 3) indicates 2 elements along the first axis, 2 elements along the second axis, and 3 elements along the third axis.
To count the number of elements within an array type:
print(f'Number of elements array one:{one_dim.size}')
print(f'Number of elements array two-1:{two_dim_1.size}')
print(f'Number of elements array two-2:{two_dim_2.size}')
print(f'Number of elements array three:{three_dim.size}')
Number of elements array one:3
Number of elements array two-1:3
Number of elements array two-2:6
Number of elements array three:12
NumPy utilizes different data types (more on this later) to represent data, which can be inspected as:
print(f'Data type array one:{one_dim.dtype}')
print(f'Data type array two-1:{two_dim_1.dtype}')
print(f'Data type array two-2:{two_dim_2.dtype}')
print(f'Data type array three:{three_dim.dtype}')
Data type array one:int64
Data type array two-1:int64
Data type array two-2:int64
Data type array three:int64
Array creation
NumPy offers several alternatives to create arrays.
I will review three cases:
- Conversion from other Python structures
- Intrinsic
NumPyarray creation objects - Use of special library functions
Conversion from other Python structures
In the previous section, I used the array method to create an array from a Python list. This is an example of array creation from the conversion of an array-like Python object.
Lists, tuples, and sets are array-like Python objects that serve as options for this method.
array_list = np.array([1, 2, 3])
array_tuple = np.array(((1, 2, 3), (4, 5, 6)))
array_set = np.array({"pikachu", "snorlax", "charizard"})
print(f'Array from list:\n{array_list}\n')
print(f'Array from tuple:\n{array_tuple}\n')
print(f'Array from set:\n{array_set}')
Array from list:
[1 2 3]
Array from tuple:
[[1 2 3]
[4 5 6]]
Array from set:
{'pikachu', 'snorlax', 'charizard'}
Intrinsic NumPy array creation objects
Manual input of data into arrays can be cumbersome, so NumPy offers a series of convenience methods to create arrays for special cases, like zeros, ones, and others. Below some common examples.
# zeros
zeros = np.zeros(5)
# ones
ones = np.ones((3, 3))
# arange
arange = np.arange(1, 10, 2)
# empty
empty = np.empty([2, 2])
# linspace
linespace = np.linspace(-1.0, 1.0, num=10)
# full
full = np.full((3,3), -2)
# indices
indices = np.indices((3,3))
print(f'Array of zeros:\n{zeros}\n')
print(f'Array of ones:\n{ones}\n')
print(f'Array of empty entries:\n{empty}\n')
print(f'Evenly spaced array in a range:\n{linespace}\n')
print(f'Array with same number on each entry:\n{full}\n')
print(f'Array from indices:\n{indices}\n')
Array of zeros:
[0. 0. 0. 0. 0.]
Array of ones:
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
Array of empty entries:
[[4.67794427e-310 6.90921830e-310]
[0.00000000e+000 0.00000000e+000]]
Evenly spaced array in a range:
[-1. -0.77777778 -0.55555556 -0.33333333 -0.11111111 0.11111111
0.33333333 0.55555556 0.77777778 1. ]
Array with same number on each entry:
[[-2 -2 -2]
[-2 -2 -2]
[-2 -2 -2]]
Array from indices:
[[[0 0 0]
[1 1 1]
[2 2 2]]
[[0 1 2]
[0 1 2]
[0 1 2]]]
- The
zeromethod generates an array of zeros of shape defined by a tuple passed to the function - The
onesmethod generates an array of ones of shape defined by a tuple passed to the function - The
emptymethod generates an empty array (although very small numbers will be printed) of shape defined by a tuple passed to the function - The
linespacemethod generates an array of evenly spaced entries given a range and a step size - The
fullmethod returns an array of shape defined by a tuple passed to the function filled with the same value (third argument outside the tuple) - The
indicesmethod generates an array representing the indices of the grid
Use of special library functions
NumPy has a large list of special cases functions that generate arrays, which are too large and seemingly disconnected to enumerate. Here are a few examples:
# diagonal array
diagonal = np.diag([1, 2, 3], k=0)
# identity
identity = np.identity(3)
# eye
eye = np.eye(4, k=1)
# rand
rand = np.random.rand(3,2)
print(f'Diagonal matrix from array-like structure:\n{diagonal}\n')
print(f'Identity matrix:\n{identity}\n')
print(f'Diagonal matrix with ones and zeros elsewhere:\n{eye}\n')
print(f'Array of random numbers sampled from a uniform distribution:\n{rand}')
Diagonal matrix from array-like structure:
[[1 0 0]
[0 2 0]
[0 0 3]]
Identity matrix:
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
Diagonal matrix with ones and zeros elsewhere:
[[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]
[0. 0. 0. 0.]]
Array of random numbers sampled from a uniform distribution:
[[0.75060485 0.07962041]
[0.36030122 0.11582055]
[0.57917376 0.93888782]]
- The
diagonalfunction returns an array with the numbers in the diagonal and zeros elsewhere - The
identityfunction returns an identity matrix - The
eyefunction returns an array with ones on the diagonal and zeros elsewhere - The
random.randfunction returns an array of random numbers sampled from a uniform distribution
Vectorization
I claimed “pure” Python is slow. One of the culprits of such slowness is Python’s loops. Loops are bad for performance for complicated reasons related to Python design as a dynamically typed language. The shortest answer to why loops are slow is that Python takes multiple actions for each call (e.g., it access memory several times, type checking, etc.), that compound and hurt performance the more loops you execute.
In scientific computing we want speed, meaning we want to get rid of loops. This is precisely what’s vectorization all about: getting rid of loops by performing computations on multiple components of a vector at the same time. Hence, performing operations in “vector” form. In NumPy, vectors can be interpreted as an array, so we could call this “arrayization” if you will, but that sounds funny and weird.
Here is how vectorization looks like conceptually.

Now let’s compare the performance gain of vectorization against looping in a simple sum.
x = np.random.rand(100)
y = np.random.rand(100)
Sum two array with a Python loop (non-vectorized)
%%timeit
for i in range(0, len(x)):
x[i] + y[i]
33 µs ± 447 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Sum arrays with NumPy (vectorized)
%%timeit
x+y;
505 ns ± 4.17 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
As you can see, the NumPy vectorized implementation is several orders of magnitude faster. In the runs I’ve done, approximately 67 times faster (~32 microsecond against ~0.49 microseconds).
Such minuscule fractions of time may not be important for you know, but consider that we are only adding up two arrays of 100 numbers. In modern data science and machine learning applications, hundreds of thousands and even millions of computations are required to fit any model, and most of the time you will want to fit multiple models several times. Just cut or multiply everything by about 70: the model that takes 1 minute to run, will take 70 minutes, and the model that takes one day can take over two months. I do not know about you, but I do not have all that time to spare.
In the next section, we cover array mathematics with NumPy, which essentially are vectorized operations.
Array mathematics and element-wise operations
Array arithmetic
As in regular mathematics, array arithmetic is fundamentally about addition, subtraction, multiplication, and division. In NumPy, this kind of operations are performed element-wise. Take the following example:
As in this example, NumPy will add the first elements of each array together, the second elements of each array together, and the third elements of each array together. Hence, element-wise addition. The same can be extrapolated to multi-dimensional arrays. Consider the following example:
The logic is the same: the top-left elements in each array are added together, the top-right elements of each array are added together, and so on. Subtraction, division, multiplication, exponentiation, logarithms, roots, and many other algebraic operations (or arithmetic depending on whom you ask), will be performed in the same manner.
Here there is a list of common arithmetic operations.
a = np.arange(1, 10).reshape((3,3))
b = np.arange(10,19).reshape((3,3))
addition = a + b
subtraction = a - b
multiplication = a * b
true_division = a / b
floor_division = a // b
remainder = np.remainder(a, b)
print(f'Array a:\n{a}\n')
print(f'Array b:\n{b}\n')
print(f'Addition of a and b:\n{addition}\n')
print(f'Subtraction of a and b:\n{subtraction}\n')
print(f'Multiplication of a and b:\n{multiplication}\n')
print(f'True divition of a and b:\n{true_division}\n')
print(f'Floor division of a and b:\n{floor_division}\n')
print(f'Remainder of a and b:\n{remainder}')
Array a:
[[1 2 3]
[4 5 6]
[7 8 9]]
Array b:
[[10 11 12]
[13 14 15]
[16 17 18]]
Addition of a and b:
[[11 13 15]
[17 19 21]
[23 25 27]]
Subtraction of a and b:
[[-9 -9 -9]
[-9 -9 -9]
[-9 -9 -9]]
Multiplication of a and b:
[[ 10 22 36]
[ 52 70 90]
[112 136 162]]
True divition of a and b:
[[0.1 0.18181818 0.25 ]
[0.30769231 0.35714286 0.4 ]
[0.4375 0.47058824 0.5 ]]
Floor division of a and b:
[[0 0 0]
[0 0 0]
[0 0 0]]
Remainder of a and b:
[[1 2 3]
[4 5 6]
[7 8 9]]
What do you think will happen if we try to multiply a 3x3 array by a scalar (a single number? There are some options:
- The operation will fail, as their shapes do not match
- Just the first element of the array will be multiplied by the scalar
- All elements of the array will be multiplied by the scalar regardless
Let’s try it out.
array_scalar = a * 2
print(f'3x3 array:\n{a}\n')
print(f'3x3 array times an scalar:\n{array_scalar}')
3x3 array:
[[1 2 3]
[4 5 6]
[7 8 9]]
3x3 array times an scalar:
[[ 2 4 6]
[ 8 10 12]
[14 16 18]]
Each element of the array was multiplied by 2. How does this even work? One option is to “loop” over each of array and multiply by 3 sequentially. But that it is slow, and NumPy is all about speed. What happens is that the scalar is “broadcast” to match the shape of the array BEFORE multiplication. In practice, what we have is a 3x3 array times a 3x3 array of 2s as:
Broadcasting will make computation way faster than looping. There is more to say about broadcasting, and I will cover it more in-depth in a later section. For now, this should help you to understand how element-wise operations work in NumPy
Trigonometric functions
NumPy provides a series of convenient functions for trigonometric calculations, which also operate in an element-wise fashion.
There are several trigonometric functions in NumPy (see here). Below a couple of the most common ones.
x = np.linspace(-4, 4, 200)
# sin function
sin = np.sin(x)
# cosine function
cos = np.cos(x)
# tangent function
tan = np.tan(x)
Let’s plot to see the outcome
import matplotlib.pylab as plt
plt.style.use('dark_background')
%config InlineBackend.figure_format = 'retina' # to get high resolution images
fig, (ax1, ax2, ax3) = plt.subplots(3, 1)
ax1.plot(x, sin)
ax1.set_title("sin")
ax2.plot(x, cos)
ax2.set_title("cos")
ax3.plot(x, tan)
ax3.set_title("tan")
plt.tight_layout()
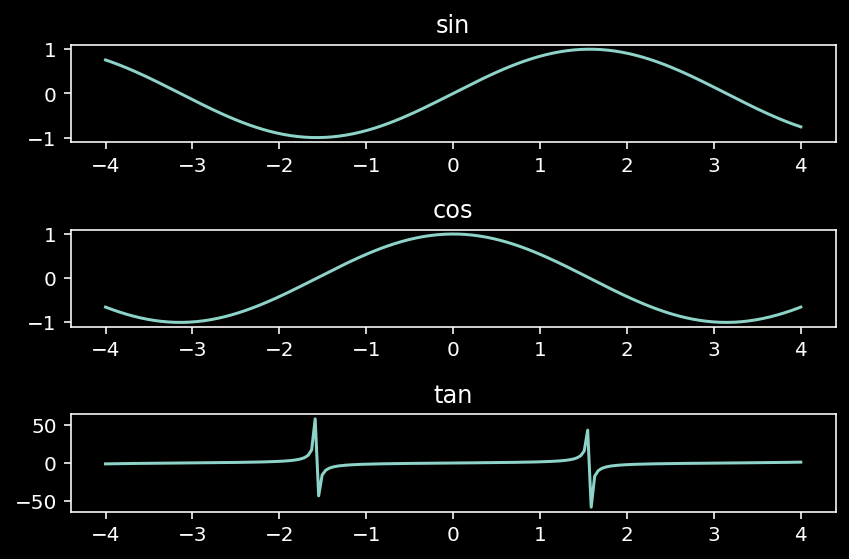
Hyperbolic functions
Hyperbolic functions are like trigonometric functions but for the hyperbola rather than for the circle. NumPy also incorporate several cases (see here).
y = np.linspace(-4, 4, 200)
# sin function
sinh = np.sinh(y)
# cosine function
cosh = np.cosh(y)
# tangent function
tanh = np.tanh(y)
fig, (ax1, ax2, ax3) = plt.subplots(3, 1)
ax1.plot(y, sin)
ax1.set_title("sinh")
ax2.plot(y, cos)
ax2.set_title("cosh")
ax3.plot(y, tan)
ax3.set_title("tanh")
plt.tight_layout()
Rounding
Rounding is a delicate subject as rounding errors when compounded over sequences of operations, can completely mess up your results. It is also a common operation for presenting and plotting results to others. Rounding is applied element-wise.
Let’s generate a sequence of random decimal numbers to see the effect of different rounding procedures available in NumPy (see here).
decimals = np.linspace(0.11111111, 0.99999999, 10)
# rounding
around = np.around(decimals, 3)
# rounding
round_ = np.round(decimals, 3)
# rounding to integer
rint = np.rint(decimals)
# rounding integer towards zero
fix = np.fix(decimals)
# round to the floor
floor = np.floor(decimals)
# round to the ceiling
ceil = np.ceil(decimals)
print(f"Array of decimals:\n{decimals}\n")
print(f"'around' round to the given number of decimals:\n{around}\n")
print(f"'round' yields identical results than 'around':\n{round_}\n")
print(f"'rint' round to the nearest integer:\n{rint}\n")
print(f"'fix' round to the nearest integer towars zero:\n{fix}\n")
print(f"'floor' round to the floor of the input:\n{floor}\n")
print(f"'ceil' round to the ceiling of the input:\n{ceil}")
Array of decimals:
[0.11111111 0.20987654 0.30864197 0.4074074 0.50617283 0.60493827
0.7037037 0.80246913 0.90123456 0.99999999]
'around' round to the given number of decimals:
[0.111 0.21 0.309 0.407 0.506 0.605 0.704 0.802 0.901 1. ]
'round' yields identical results than 'around':
[0.111 0.21 0.309 0.407 0.506 0.605 0.704 0.802 0.901 1. ]
'rint' round to the nearest integer:
[0. 0. 0. 0. 1. 1. 1. 1. 1. 1.]
'fix' round to the nearest integer towars zero:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
'floor' round to the floor of the input:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
'ceil' round to the ceiling of the input:
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
Exponents and logarithms
Exponents and logarithms are often used in computations related to probability and statistics. NumPy incorporate several of the common ones (see here).
z = np.array([0.1, 1, np.e, np.pi])
# exponent
exp = np.exp(z)
# exponent(x) -1
expm1 = np.expm1(z)
# 2^P
exp2 = np.exp2(z)
# natural log
log = np.log(z)
# log base 10
log10 = np.log10(z)
# log base 2
log2 = np.log2(z)
print(f'Compute exponential element-wise:\n{exp}\n')
print(f"Compute 'exp(x) - 1' with greater precision for small values:\n{expm1}\n")
print(f"Compute '2**p' for all elements p in the array:\n{exp2}\n")
print(f'Compute natural logarithm element-wise:\n{log}\n')
print(f'Compute base 10 logarithm element-wise:\n{log10}\n')
print(f'Compute base 2 logarithm element-wise:\n{log2}\n')
Compute exponential element-wise:
[ 1.10517092 2.71828183 15.15426224 23.14069263]
Compute 'exp(x) - 1' with greater precision for small values:
[ 0.10517092 1.71828183 14.15426224 22.14069263]
Compute '2**p' for all elements p in the array:
[1.07177346 2. 6.58088599 8.82497783]
Compute natural logarithm element-wise:
[-2.30258509 0. 1. 1.14472989]
Compute base 10 logarithm element-wise:
[-1. 0. 0.43429448 0.49714987]
Compute base 2 logarithm element-wise:
[-3.32192809 0. 1.44269504 1.65149613]
Other miscellaneous element-wise operations
There are several other common mathematical operations available in NumPy, that are routinely used at different stages of the data processing and modeling.
Here is a list of several important ones. As always, you can find more in the NumPy documentation.
array_1 = np.arange(-9,9, 2)
array_2 = np.arange(-9,9, 2).reshape((3,3))
# sum over
sum_1, sum_2, sum_3 = np.sum(array_1), np.sum(array_2, axis=0), np.sum(array_2, axis=1)
# take product
prod_1, prod_2, prod_3 = np.prod(array_1), np.prod(array_2, axis=0), np.prod(array_2, axis=1)
# cumulative sum
cumsum_1, cumsum_2, cumsum_3 = np.cumsum(array_1), np.cumsum(array_2, axis=0), np.cumsum(array_2, axis=1)
# clip values
clip_1, clip_2 = np.clip(array_1, 2, 8), np.clip(array_2, 2, 8)
# take absolute value
absolute_1, absolute_2 = np.absolute(array_1), np.absolute(array_2)
# take square root
sqrt_1, sqrt_2 = np.sqrt(np.absolute(array_1)), np.sqrt(np.absolute(array_2))
# take the square power
square_1, square_2 = np.square(array_1), np.square(array_2)
# sign function
sign_1, sign_2 = np.sign(array_1), np.sign(array_2)
# n power
power = np.power(np.absolute(array_1), np.absolute(array_1))
print(f"'sum-1' sum array elements:{sum_1}\n"f"'sum-2' sum rows:{sum_2}\n"f"'sum-3' sum cols:{sum_3}\n")
print(f"'prod-1' product array elements:{prod_1}\n"f"'prod-2' product rows: {prod_2}\n"f"'prod-3' product cols: {prod_3}\n")
print(f"'cumsum_1' cumulative sum array elements:\n{cumsum_1}\n"f"'cumsum_2' cumulative sum rows:\n{cumsum_2}\n"f"'cumsum_3' cumulative sum cols:\n{cumsum_3}\n")
print(f"'clip-1' limit range of values (2-8):\n{clip_1}\n"f"'clip-2' limit range of values (2-8):\n{clip_2}\n")
print(f"'absolute-1' absolute value array elements:\n{absolute_1}\n"f"'absolute-2' absolute value array elements:\n{absolute_2}\n")
print(f"'sqrt-1' non-negative square root array elements:\n{sqrt_1}\n"f"'sqrt-2' non-negative square root array elements:\n{sqrt_2}\n")
print(f"'square-1' square array elements: \n{square_1}\n"f"'square-2' square array elements: \n{square_2}\n")
print(f"'sign-1' sign indication of array elements:\n{sign_1}\n"f"'sign-2' sign indication of array elements:\n{sign_2}\n")
print(f"'power' elements of first array raised to powers from the second:\n{power}\n")
'sum-1' sum array elements:-9
'sum-2' sum rows:[-9 -3 3]
'sum-3' sum cols:[-21 -3 15]
'prod-1' product array elements:-99225
'prod-2' product rows: [ 81 35 -35]
'prod-3' product cols: [-315 3 105]
'cumsum_1' cumulative sum array elements:
[ -9 -16 -21 -24 -25 -24 -21 -16 -9]
'cumsum_2' cumulative sum rows:
[[ -9 -7 -5]
[-12 -8 -4]
[ -9 -3 3]]
'cumsum_3' cumulative sum cols:
[[ -9 -16 -21]
[ -3 -4 -3]
[ 3 8 15]]
'clip-1' limit range of values (2-8):
[2 2 2 2 2 2 3 5 7]
'clip-2' limit range of values (2-8):
[[2 2 2]
[2 2 2]
[3 5 7]]
'absolute-1' absolute value array elements:
[9 7 5 3 1 1 3 5 7]
'absolute-2' absolute value array elements:
[[9 7 5]
[3 1 1]
[3 5 7]]
'sqrt-1' non-negative square root array elements:
[3. 2.64575131 2.23606798 1.73205081 1. 1.
1.73205081 2.23606798 2.64575131]
'sqrt-2' non-negative square root array elements:
[[3. 2.64575131 2.23606798]
[1.73205081 1. 1. ]
[1.73205081 2.23606798 2.64575131]]
'square-1' square array elements:
[81 49 25 9 1 1 9 25 49]
'square-2' square array elements:
[[81 49 25]
[ 9 1 1]
[ 9 25 49]]
'sign-1' sign indication of array elements:
[-1 -1 -1 -1 -1 1 1 1 1]
'sign-2' sign indication of array elements:
[[-1 -1 -1]
[-1 -1 1]
[ 1 1 1]]
'power' elements of first array raised to powers from the second:
[387420489 823543 3125 27 1 1 27
3125 823543]
Array data type and conversions
I mentioned NumPy arrays can contain a single data type. This constraint makes data storing and manipulation much more efficient than working with mixed type arrays (like Python lists), which is a priority for NumPy.
Data types in NumPy is a relatively complicated subject, particularly if you are not familiar with C or memory allocation. For our purposes, some basic data types are worth knowing:
np.bool_: used to represent “Booleans” (True or False)np.int: used to integers numbersnp.unit: used to represent positive integers or “unsigned” integersnp.float: used to represent real numbers (decimals, fractions, etc) or “floating point” numbersnp.complex: used to represent complex numbers
In my experience, booleans, integers, and float point data types are the ones that you end up using the most. At least explicitly. Other data types are used all the time, but you do not have to worry about it because NumPy takes care of it for you. Since Python is a “dynamically typed” language, which simply means that you do not have to tell the computer what data type you will use (Python does this for you), most of the time you do not need to indicate which data type you will use.
For instance, if you simply define and an array of values, NumPy will decide what data type to allocate for each:
bools = np.array([True, False])
ints = np.full((2,2), 1)
floats = np.ones(5)
unsigned = np.arange(3, dtype=np.uint8)
complexs = np.array([+1j, +2j, +3j])
unicode = np.array(["Catbug", "Chris", "Danny", "Wallow", "Beth"])
print(f'Booleans :{bools.dtype}')
print(f'Integers :{ints.dtype}')
print(f'Floats :{floats.dtype}')
print(f'Unsigned :{unsigned.dtype}')
print(f'Complexs :{complexs.dtype}')
print(f'Unicode :{unicode.dtype}')
Booleans :bool
Integers :int64
Floats :float64
Unsigned :uint8
Complexs :complex128
Unicode :<U6
In some instances, you may want to explicitly indicate the data type. Here are some examples of how you can do that:
int_16 = np.array([1, 2, 3, 4], dtype='int16')
float_32 = np.array([1, 2, 3, 4], dtype='float32')
unsigned_int_8 = np.arange(3, dtype='uint8')
print(f'Integer 16 bytes data type: { int_16.dtype}')
print(f'Float 32 bytes data type: {float_32.dtype}')
print(f'Unsigned integer 8 bytes data type: {unsigned_int_8.dtype}')
Integer 16 bytes data type: int16
Float 32 bytes data type: float32
Unsigned integer 8 bytes data type: uint8
Note that the numbers after the data type, like 8, 16, 32, and 64, indicate the number of bytes is allocated to represent each element of the array. The higher the number, the more memory.
There are several reasons why you may want to explicitly indicate the data type. One of the most common reasons is memory efficiency. If you know your range of numbers in a variable is small positive numbers, utilizing 8 bytes unsigned integers will use significantly less memory than a 32 bytes integer. Now, this will be an issue only with massive datasets, meaning datasets that make your computer to have difficulty processing your data, as it is not clear what “massive” means without context.
A final operation you may want to do, is to change the data type of an array. For instance, let’s say you want to stack two arrays, but one has a floating-point data type and the other integers. Recall that NumPy arrays can have a single data type. Let’s see an example.
int_array = np.arange(10, dtype='int')
float_array = np.arange(10, dtype='float')
print(f'Array 1: {int_array}, data type:{int_array.dtype}')
print(f'Array 2: {float_array}, data type:{float_array.dtype}')
Array 1: [0 1 2 3 4 5 6 7 8 9], data type:int64
Array 2: [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.], data type:float64
Let’s first stack the arrays as they are:
stacked_arrays = np.stack((int_array, float_array))
print(f'Stacked arrays as they are:\n{stacked_arrays},\ndata type:{stacked_arrays.dtype}')
Stacked arrays as they are:
[[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]],
data type:float64
As you can see, NumPy “upcasted” the data type of lower precision, the int64, to the data type of higher precision, the float64. This is simply because int64 can’t represent float point or real numbers, only integers or natural numbers. But float64 can represent integers. So it is the smart choice to make things work.
Now, you may want to keep everything as integers, for whatever reason. If so, this is what you need to do. First, convert the float64 array to an int64 array as:
int_array_2 = float_array.astype('int64')
And now stack things together.
stacked_arrays_2 = np.stack((int_array, int_array_2))
print(f'Stacked arrays after conversion:\n{stacked_arrays_2},\ndata type:{stacked_arrays_2.dtype}')
Stacked arrays after conversion:
[[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]],
data type:int64
There you go, the array is composed by integers of 64 bytes now.
Let’s say you want to save memory by converting the new array to a lower byte representation, like int 8. This is known as “downcasting”, i.e., the opposite of “upcasting”. For this you simply need to:
stacked_arrays_3 = stacked_arrays_2.astype('int8')
print(f'Stacked arrays after downcasting:\n{stacked_arrays_3},\ndata type:{stacked_arrays_3.dtype}')
Stacked arrays after downcasting:
[[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]],
data type:int8
You can check and compare the memory “footprint” of each array as:
print(f'Memory size Int64 array:{stacked_arrays_2.nbytes}')
print(f'Memory size Int8 array:{stacked_arrays_3.nbytes}')
Memory size Int64 array:160
Memory size Int8 array:20
The memory footprint has been reduced by a factor of 8. This may not sound like a lot, but if you are working with a dataset of size, let’s say, 8 gigabytes, you can reduce such memory usage to only 1 gigabyte, which will also do data manipulation faster.
Array manipulation
The shape of an array is given by the number of elements along each axis. Now, if you think in an array as composed by little boxes or LEGO pieces, you can start to think of how those pieces can be rearranged in different shapes. For example, a 2 x 2 array could be “flattened” to be a 1 x 4 array, or maybe you could “swap” the rows and columns of the array, by moving the little boxes around or even take away a couple of pieces reducing the array to a 1 x 2 shape.
These kinds of operations are extremely common in any kind of data manipulation, and it is one of the most important skills to acquire. Some people prefer to convert NumPy arrays to Pandas DataFrames, as Pandas provide several easy to use functions to manipulate arrays. Nonetheless, manipulating arrays in NumPy it is not that much harder, it can save you time and effort by preventing you to going back and forth with Pandas, and well, this is a NumPy tutorial, so we are here to learn NumPy way.
Array shape manipulation
Arrays can be changed with or without changing is data. This is equivalent to the difference between rearranging LEGO blocks with or without adding/removing pieces.
The reshape method changes the shape of an array without changing its data.
array_1 = np.array([[1, 2, 3],
[4, 5, 6]])
print(f'Array-1 shape: {array_1.shape}')
Array-1 shape: (2, 3)
Array-1 has shape (2, 3), meaning it has 2 rows and 3 columns.
# the two syntaxs below are equivalent
array_2 = array_1.reshape(3,2)
array_3 = np.reshape(array_1, (1,6))
print(f'Array-2:\n{array_2},\nshape: {array_2.shape}\n')
print(f'Array-3:\n{array_3},\nshape: {array_3.shape}')
Array-2:
[[1 2]
[3 4]
[5 6]],
shape: (3, 2)
Array-3:
[[1 2 3 4 5 6]],
shape: (1, 6)
Array-2 and Array-3 preserve the number of elements of Array-1.
Flattening an array, this is, collapsing all values into a single axis or dimension, can be done in two manners:
array_1_ravel = array_1.ravel()
array_1_flatt = array_1.flatten()
print(f'Array-1 ravel:\n{array_1_ravel},\nshape: {array_1_ravel.shape}\n')
print(f'Array-1 flattened:\n{array_1_flatt},\nshape: {array_1_flatt.shape}')
Array-1 ravel:
[1 2 3 4 5 6],
shape: (6,)
Array-1 flattened:
[1 2 3 4 5 6],
shape: (6,)
Why on earth are there two methods to do exactly the same? The answer is that they are not doing the same: ravel() returns a ‘view’ of the original array, whereas flatten() returns an independent ‘copy’ of it. Views or images are just “pointers” to the original array in memory, whereas copies have their own space in memory. I’ll cover this in-depth later.
Another thing you might have realized is that Array-3 has the same elements as Array-1-ravel and Array-1-flattened, but it has an extra pair of [] and shape (1,6) instead of (,6). What is going on here?
Put simply, internally, NumPy arrays have two parts: the information itself and information about how to interpret/read the array. In the case of the shape information, this indicates how many “indices” are associated with an array. The (1,6) is saying that there two indices identifying the array: the number 1 for all the elements, and the numbers from 1 to 6 for each element. This makes sense if you think in arrays as matrices or excel sheets: the first element is in the first row and first column (1,1), the second in the first row and the second column (1, 2), and so on.
However, If you think about it, you don’t need two indices to identify the elements of a one-dimensional array. After all, when we count things we do not count “1 and 1, 1 and 2, 1 and 3, 1 and 4…” and so on. The (6,) is just saying that there is a single index identifying each of the 6 elements of the array, which makes perfect sense. The first element of the array is in position one (1,), the second in position two (2,), and so on.
Now you may be wondering. Why then add a 1 as an index if it’s unnecessary? Since NumPy supports multi-dimensional arrays, technically, the (1,6) is indicating the array has TWO dimensions or axes instead of one. “BUT, the array has just one dimension, right?” Yes and no. The thing is such array can be represented as either: as a collection of elements along one dimension or as a collection of elements along two dimensions, with the caveat that the first dimension has all the data, and the other is basically “empty” or “flat”, but assigned to it. Just like with the first element is in the first row and first column (1,1)” idea.
If you are familiar with linear algebra or geometry, you should know that a square is an object with two dimensions, but that can ‘live’ in three, four, five, a million, or any number of dimensions. Essentially, higher-dimensional spaces can contain objects with fewer dimensions, but not the other way around. You can’t fit a sphere in a plane. The misunderstanding, in my view, comes from the tendency to think in data as two-dimensional grid-like objects, when in practice does not need to be like that necessarily. People like to think in NumPy arrays as matrices, vectors, tensors, etc., but they aren’t, they are arrays with one or more dimensions. Period.
This whole discussion may sound like I am beating around the bushes, but I am not. Dimensionality mismatch is one of the most important sources of errors, misunderstandings, and frustrations when working with NumPy arrays. If you ever do anything related to linear algebra, like pretty much all of machine learning and statistics, you need to have a firm understanding of how dimensions work in NumPy.
Related to our previous discussion, a “trick” you may want to be aware of, is how to add dimensions to an array, since you will find cases where this can be an issue.
a = np.array([1, 2, 3])
print(f'Array a: {a}\n')
print(f'Array a shape: {a.shape}\n')
print(f'Array a dimensions: {a.ndim}\n')
Array a: [1 2 3]
Array a shape: (3,)
Array a dimensions: 1
To add a new dimension and keep array a as “row” in a two-dimensional “matrix”, use the np.newaxis object:
a_row = a[np.newaxis, :]
print(f'Array a: {a_row}\n')
print(f'Array a shape: {a_row.shape}\n')
print(f'Array a dimensions: {a_row.ndim}\n')
Array a: [[1 2 3]]
Array a shape: (1, 3)
Array a dimensions: 2
To add a new dimension and keep array a as “column” in a two-dimensional “matrix”, just flip the order of the arguments:
a_col = a[:, np.newaxis]
print(f'Array a:\n{a_col}\n')
print(f'Array a shape: {a_col.shape}\n')
print(f'Array a dimensions: {a_col.ndim}\n')
Array a:
[[1]
[2]
[3]]
Array a shape: (3, 1)
Array a dimensions: 2
Array transpose-like operations
Transposing means to “swap” or interchange the position and elements between two or more axes.
The most common operation is the plain Transpose operation, where the axes get permuted.
array_1 = np.arange(4).reshape((2,2))# two dimensional array
array_2 = np.arange(12).reshape((3,2,2)) # three dimensional array
print(f'Array-1:\n{array_1},\nshape:{array_1.shape}\n')
print(f'Array-2:\n{array_2},\nshape:{array_2.shape}')
Array-1:
[[0 1]
[2 3]],
shape:(2, 2)
Array-2:
[[[ 0 1]
[ 2 3]]
[[ 4 5]
[ 6 7]]
[[ 8 9]
[10 11]]],
shape:(3, 2, 2)
Now let’s transpose both:
array_1_T = array_1.T
array_2_T = array_2.T
print(f'Array-1 transposed:\n{array_1_T},\nshape:{array_1_T.shape}\n')
print(f'Array-2 transposed:\n{array_2_T},\nshape:{array_2_T.shape}')
Array-1 transposed:
[[0 2]
[1 3]],
shape:(2, 2)
Array-2 transposed:
[[[ 0 4 8]
[ 2 6 10]]
[[ 1 5 9]
[ 3 7 11]]],
shape:(2, 2, 3)
Array-1 has swapped the rows for the columns. Array-2 has reshaped from a three 2x2 arrays, into two 2x3 arrays. This is because of the indices “cycle” such that the third index pass to the first place, the second to the third, and the first to the second.
The moveaxis method is more flexible than transpose as it allows for an arbitrary rearrangement of axes to new positions. The syntax is simple: np.moveaxis(original-array, origin-position-axis-to-move, destiny-position-axis-to-move). Recall that axes are index as (0, 1, 2, …0).
array_move_2_3_4 = np.arange(24).reshape((2,3,4))
array_move_2_4_3 = np.moveaxis(array_move_2_3_4, 2, 1) # move axis in position two to position one
array_move_3_2_4 = np.moveaxis(array_move_2_3_4, 0, 1) # move axis in position zero to position one
array_move_3_4_2 = np.moveaxis(array_move_2_3_4, 0, 2) # move axist in the zero position to position two
array_move_4_2_3 = np.moveaxis(array_move_2_3_4, [2, 1], [0, 2]) # move axes in positions two and one, to positions zero and two
array_move_4_3_2 = np.moveaxis(array_move_2_3_4, [2, 0], [0, 2]) # move axes in positions two and zero, to positions zero and two
print(f'Original order: {array_move_2_3_4.shape}\n')
print(f'New axes order 1: {array_move_2_4_3.shape}\n')
print(f'New axes order 2: {array_move_3_2_4.shape}\n')
print(f'New axes order 3: {array_move_3_4_2.shape}\n')
print(f'New axes order 4: {array_move_4_2_3.shape}\n')
print(f'New axes order 5: {array_move_4_3_2.shape}')
Original order: (2, 3, 4)
New axes order 1: (2, 4, 3)
New axes order 2: (3, 2, 4)
New axes order 3: (3, 4, 2)
New axes order 4: (4, 2, 3)
New axes order 5: (4, 3, 2)
Array dimension manipulation
Intentionally changing the dimensions of arrays is an operation done mostly, in my experience, when you want to combine arrays or to do mathematical operations with two or more arrays. In the dimensions do not match or are not defined in a certain manner, joining or calculations won’t work, or would work in unexpected manners.
In this section, I’ll mention just two operations: expanding dimensions and squeezing dimensions, which are opposite operations. There is a third extremely important dimension manipulation operation: broadcasting. Broadcasting is not just important but rather complicated to explain so I will give its own section after this one.
Expanding dimensions it is always possible as higher-dimensional objects can always contain lower-dimensional objects: you can fit a two-dimensional piece of paper inside a three-dimensional box, but not the other way around (I know! paper is three dimensional, but I hope you get the point).
array_one = np.array([1, 2, 3])
array_two = np.array([[1, 2, 3], [4, 5, 6]])
array_one_expand = np.expand_dims(array_one, axis=0)
array_two_expand = np.expand_dims(array_two, axis=0)
print(f'One dimensional array: \n{array_one} \nshape: {array_one.shape}\n')
print(f'One dimensional array expanded: \n{array_one_expand} \nshape: {array_one_expand.shape}\n')
print(f'Two dimensional array: \n{array_two} \nshape: {array_two.shape}\n')
print(f'Two dimensional array expanded: \n{array_two_expand} \nshape: {array_two_expand.shape}\n')
One dimensional array:
[1 2 3]
shape: (3,)
One dimensional array expanded:
[[1 2 3]]
shape: (1, 3)
Two dimensional array:
[[1 2 3]
[4 5 6]]
shape: (2, 3)
Two dimensional array expanded:
[[[1 2 3]
[4 5 6]]]
shape: (1, 2, 3)
As you can see, both arrays gain an extra dimension when expanded.
Let’s bring the arrays back to their original dimensionality with the opposite operation: squeezing.
array_one_squeez = np.squeeze(array_one_expand, axis=0)
array_two_squeez = np.squeeze(array_two_expand, axis=0)
print(f'Three dimensional array squeezed: \n{array_one_squeez} \nshape: {array_one_squeez.shape}\n')
print(f'Three dimensional array squeezed: \n{array_two_squeez} \nshape: {array_two_squeez.shape}')
Three dimensional array squeezed:
[1 2 3]
shape: (3,)
Three dimensional array squeezed:
[[1 2 3]
[4 5 6]]
shape: (2, 3)
We can check the squeezed arrays have the same dimensionality that the original ones as:
print(f'Are dimensions for array-one and array-one-squeezed equal?: {array_one.shape == array_one_squeez.shape}\n')
print(f'Are dimensions for array-two and array-two-squeezed equal?: {array_two.shape == array_two_squeez.shape}')
Are dimensions for array-one and array-one-squeezed equal?: True
Are dimensions for array-two and array-two-squeezed equal?: True
Array broadcasting
Broadcasting is an automatic NumPy mechanism to match the dimensionality of arrays with different shapes for element-wise operations. Broadcasting usually improves speed by means of vectorizing operations, meaning that the loop will occur in compiled C code rather than in Python, as Python looping us is resource-intensive and slow. However, there are some cases where broadcasting is not the best option.
In the array mathematics section, we saw NumPy performs several important computations element-wise, which requires having arrays with matching shapes: arrays of shape (,1), (2,2), and (4,3,2), must be multiplied by arrays with shape (,1), (2,2), and (4,3,2), to be compatible. However, there are cases where we want to multiplied arrays with shapes that do not match, for instance:
Following linear algebra conventions, we should multiply each element of $\textit{A}$ by 2. The way to get around in this in NumPy, is by broadcasting the scalar to match the shape of $\textit{A}$ as:
The scalar only gets “stretched” vertically and horizontally during computation. Now, creating copies of $x$ is memory inefficient, so NumPy does not actually copy the value in memory. This is slightly inaccurate, but in a nutshell, broadcasting works by reusing the original value (the This may not be evident in the $\textit{A}x$ example, but just imagine a (1,000,000, 100) array. In such a case, NumPy would have to duplicate the size of the dataset, i.e., to create 100,000,000 of values just to perform matrix-scalar multiplication.
Not all arrays can be broadcast. They must meet certain conditions, the “Broadcasting rule”, which according to the NumPy documentation states:
“In order to broadcast, the size of the trailing axes for both arrays in an operation must either be the same size or one of them must be one.”
This is easier to understand visually. The figure below shows the cases where broadcasting is valid, and the next one when it is not.

For instance:
a = np.ones((2,2))
b = np.ones (1)
print(f'(2,2) array:\n{a}\nshape: {a.shape}]\n')
print(f'(1, ) array:\n{b}\nshape: {b.shape}]\n')
print(f'Element-wise operations are valid between a and b:\n{a + b}')
(2,2) array:
[[1. 1.]
[1. 1.]]
shape: (2, 2)]
(1, ) array:
[1.]
shape: (1,)]
Element-wise operations are valid between a and b:
[[2. 2.]
[2. 2.]]
Invalid operations are variations of:

We can verify that the above operation does not work:
a = np.ones((2,2))
b = np.ones((3))
# a + b
In this case, we get a “ValueError: operands could not be broadcast together” error message.
Most of the time you won’t need to think in dimension matching beforehand. Either it will work or NumPy will let you know dimensions do not match. The important part is to be aware of broadcasting mechanics such that you can debug dimension mismatch problems rapidly.
Joining arrays
Joining arrays is another common operation in data processing, particularly to put together data coming from different sources. For instance, large datasets are commonly split into several sub-datasets containing different features or variables associated with the same population.
Here are all the joining methods in NumPy. Below a couple of the main methods.
base_array = np.arange(1,10).reshape((3,3))
join_array = np.arange(1,4).reshape((1,3))
concatenate = np.concatenate((base_array, join_array), axis=0)
stack = np.stack((base_array, base_array))
hstack = np.hstack((base_array, join_array.T))
vstack = np.vstack((base_array, join_array))
To concatenate arrays must have at least one equal dimension, which must be defined as the axis reference. Here we concatenate along the first axis (rows match). If you try to concatenate along the second axis the operation will fail (columns do not match).
print(f'Row-wise concatenation:\n{concatenate}\n')
Row-wise concatenation:
[[1 2 3]
[4 5 6]
[7 8 9]
[1 2 3]]
To stack arrays, all the arrays must have the same dimensions. The logic here is to generate an array with an extra dimension, like stacking LEGO pieces with the same shape.
print(f'Stacking:\n{stack}\n')
print(f'shape before stacking:{base_array.shape}\nshape after stacking:{stack.shape}')
Stacking:
[[[1 2 3]
[4 5 6]
[7 8 9]]
[[1 2 3]
[4 5 6]
[7 8 9]]]
shape before stacking:(3, 3)
shape after stacking:(2, 3, 3)
Horizontal stacking (hstack) and vertical stacking (vstack), stack arrays along the horizontal and vertical axes, i.e., column-wise and row-wise, meaning that the array will “grow” horizontally (attached to the right) and vertically (attached below), respectively.
In most cases, the same effect can be accomplished with the concatenation method along axis 1 (cols) and axis 0 (rows). To work, horizontal stacking must match along all axes but the first one, the first one being the horizontal one, or “the rows” in the 2-dimensional case. This is why we had to transpose the join_array, such that rows match. In other words, you can have an arbitrary number of columns but everything else must match. Vertical stacking is analogous: you can have an arbitrary number of rows, but columns must match.
print(f'Horizontal-wise or column-wise stacking:\n{hstack}\n')
print(f'Vertical-wise or row-wise stacking:\n{vstack}\n')
Horizontal-wise or column-wise stacking:
[[1 2 3 1]
[4 5 6 2]
[7 8 9 3]]
Vertical-wise or row-wise stacking:
[[1 2 3]
[4 5 6]
[7 8 9]
[1 2 3]]
Splitting arrays
Splitting arrays is common when you want to analyze, model, or plot a subset of the data. Also when your data size is enormous and you want to save it in chunks.
Here are all the NumPy splitting functions. Let’s explore a couple.
array_one = np.arange(9)
array_two = np.arange(8).reshape((2,2,2))
split_one, split_two = np.split(array_one, 3), np.split(array_two, 2)
array_split_one, array_split_two = np.array_split(array_one, 2), np.array_split(array_two, 3)
hsplit_one = np.hsplit(array_one, 3)
hsplit_two, vsplit_two = np.hsplit(array_two, 2), np.vsplit(array_two, 2)
The split method will work as long as you ask for a number of sub-arrays which can be obtained via equal division of the original array. For instance, array_one can be equally divided into two arrays.
print(f'Array one (9,):\n{array_one.shape}\n')
print(f'Array two (2,2,2):\n{array_two.shape}\n')
print(f'Array one is split into 3 (1,3) sub-arrays:\n{split_one[0]}\n{split_one[1]}\n{split_one[2]}\n')
print(f'Array two is split into 2 (1,2,2) sub-arrays:\n{split_two[0]}\n{split_two[1]}\n')
Array one (9,):
(9,)
Array two (2,2,2):
(2, 2, 2)
Array one is split into 3 (1,3) sub-arrays:
[0 1 2]
[3 4 5]
[6 7 8]
Array two is split into 2 (1,2,2) sub-arrays:
[[[0 1]
[2 3]]]
[[[4 5]
[6 7]]]
The array_split function provides identical functionality than the array function, with the difference that it will work even when the original array cannot be equally divided into the requested number of sub-arrays. Basically, if you try to split the array one (9,) into 2, the operation will work and the last number (the “9”) will be completely ignored. On the other hand, if you try to split an array two (2,2,2) into 3 parts, it will generate an extra empty axis.
print(f'Array one split into 2 sub-arrays:\n{array_split_one[0]}\n{array_split_one[1]}\n')
print(f'Array two split into 3 sub-arrays:\n{array_split_two[0]}\n{array_split_two[1]}\n{array_split_two[2]}\n')
Array one split into 2 sub-arrays:
[0 1 2 3 4]
[5 6 7 8]
Array two split into 3 sub-arrays:
[[[0 1]
[2 3]]]
[[[4 5]
[6 7]]]
[]
As with concatenation, horizontal split (hsplit) and vertical split (vsplit) provide equivalent functionality than the split method (split), but restricted to the horizontal and vertical axis respectively. Equal division is also a constrain here. Array one can’t be split vertically because it has only one dimension.
print(f'Array one horizontal split into 3 sub-arrays:\n{hsplit_one[0]}\n{hsplit_one[1]}\n{hsplit_one[2]}\n')
print(f'Array two horizontal split into 2 sub-arrays:\n{hsplit_two[0]}\n{hsplit_two[1]}\n')
print(f'Array two horizontal split into 2 sub-arrays:\n{vsplit_two[0]}\n{vsplit_two[1]}')
Array one horizontal split into 3 sub-arrays:
[0 1 2]
[3 4 5]
[6 7 8]
Array two horizontal split into 2 sub-arrays:
[[[0 1]]
[[4 5]]]
[[[2 3]]
[[6 7]]]
Array two horizontal split into 2 sub-arrays:
[[[0 1]
[2 3]]]
[[[4 5]
[6 7]]]
Array repetition
Arrays can be constructed or expanded via repetition. Data simulation and image manipulation are situations where you may want to use this functionality.
There are two NumPy methods that may look similar at first but they are not: tiling and repetition.
array_one = np.arange(1,4)
array_two = np.arange(1,10).reshape((3,3))
tile_one, tile_two, tile_three, tile_four = np.tile(array_one, (1,2)), np.tile(array_one, (2,1)), np.tile(array_two, (1,2)), np.tile(array_two, (2,1))
repeat_one, repeat_two = np.repeat(array_one, 2, axis=0), np.repeat(array_two, 2)
repeat_three, repeat_four = np.repeat(array_two, 2, axis=1), np.repeat(array_two, 2, axis=0)
Tiling will attach an entire copy of the array (as a block) at its right or below it. The number of copies attached is specified as a tuple, with the first indicating the number of “rows” copies and the second the number of “column” copies.
print(f'Repeat array one twice column-wise:\n{tile_one}\n')
print(f'Repeat array one twice row-wise:\n{tile_two}\n')
print(f'Repeat array two twice column-wise:\n{tile_three}\n')
print(f'Repeat array twotwice row-wise:\n{tile_four}\n')
Repeat array one twice column-wise:
[[1 2 3 1 2 3]]
Repeat array one twice row-wise:
[[1 2 3]
[1 2 3]]
Repeat array two twice column-wise:
[[1 2 3 1 2 3]
[4 5 6 4 5 6]
[7 8 9 7 8 9]]
Repeat array twotwice row-wise:
[[1 2 3]
[4 5 6]
[7 8 9]
[1 2 3]
[4 5 6]
[7 8 9]]
The repeat method will replicate the elements of the array in place. For instance:
\[\begin{bmatrix} 1 & 2 \end{bmatrix}\]Will be repeated as:
\[\begin{bmatrix} 1 & 1 & 2 & 2 \end{bmatrix}\]Instead as:
\[\begin{bmatrix} 1 & 2 & 1 & 2 \end{bmatrix}\]The latter behavior is expected from the tile method instead. The axis for repetition is specified independently as “axis=0” for rows and “axis=1” for columns.
print(f'Repeat array one twice row-wise:\n{repeat_one}\n')
print(f'Repeat array two twice and flattened into one dimension:\n{repeat_two}\n')
print(f'Repeat array two twice column-wise:\n{repeat_three}\n')
print(f'Repeat array two twice row-wise:\n{repeat_four}\n')
Repeat array one twice row-wise:
[1 1 2 2 3 3]
Repeat array two twice and flattened into one dimension:
[1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9]
Repeat array two twice column-wise:
[[1 1 2 2 3 3]
[4 4 5 5 6 6]
[7 7 8 8 9 9]]
Repeat array two twice row-wise:
[[1 2 3]
[1 2 3]
[4 5 6]
[4 5 6]
[7 8 9]
[7 8 9]]
repeat_three, repeat_four
(array([[1, 1, 2, 2, 3, 3],
[4, 4, 5, 5, 6, 6],
[7, 7, 8, 8, 9, 9]]),
array([[1, 2, 3],
[1, 2, 3],
[4, 5, 6],
[4, 5, 6],
[7, 8, 9],
[7, 8, 9]]))
Adding and removing array elements
There are several NumPy methods to add and remove elements from arrays. You may want to do this to clean a dataset, subset datasets, combine dataset, or maybe just playing a prank on someone 🤷.
array_one = np.arange(1,4)
array_two = np.arange(1,10).reshape((3,3))
array_three = np.array([[1, 1, 2, 2],
[1, 1, 2, 2],
[2, 2, 3, 3],
[2, 2, 3, 3]])
delete_one, delete_two, delete_three = np.delete(array_one, 2), np.delete(array_two, 0, 1), np.delete(array_two, 1, 0)
insert_one, insert_two, insert_three, insert_four = np.insert(array_one, 1, 9), np.insert(array_two, 5, 9), np.insert(array_two, 1, 9, axis=0), np.insert(array_two, 1, 9, axis=1)
unique_one, unique_two, unique_three = np.unique(array_three), np.unique(array_three, axis=0), np.unique(array_three, axis=1)
The delete method remove elements along the specified axis. In essence, you have to index the sub-array you want to remove to the method call.
print(f'Array one:\n{array_one}\n')
print(f'Array two:\n{array_two}\n')
print(f'Delete element in position 2 in array one:\n{delete_one}\n')
print(f'Delete column (along axis 1) in position 0 in array two:\n{delete_two}\n')
print(f'Delete row (along axis 0) in position 2 in array two:\n{delete_three}\n')
Array one:
[1 2 3]
Array two:
[[1 2 3]
[4 5 6]
[7 8 9]]
Delete element in position 2 in array one:
[1 2]
Delete column (along axis 1) in position 0 in array two:
[[2 3]
[5 6]
[8 9]]
Delete row (along axis 0) in position 2 in array two:
[[1 2 3]
[7 8 9]]
The insert method will insert elements along the specified axis. If no axis is specified the value will be inserted in a flattened version of the array. To insert values you also have to indicate the position index.
print(f'Insert a "9" at position 1 in array one:\n{insert_one}\n')
print(f'Insert a "9" at position 5 in array two:\n{insert_two}\n')
print(f'Insert a sub-array of "9s" at position 1 in array two along axis 0 (rows):\n{insert_three}\n')
print(f'Insert a sub-array of "9s" at position 1 in array two along axis 1 (cols):\n{insert_four}\n')
Insert a "9" at position 1 in array one:
[1 9 2 3]
Insert a "9" at position 5 in array two:
[1 2 3 4 5 9 6 7 8 9]
Insert a sub-array of "9s" at position 1 in array two along axis 0 (rows):
[[1 2 3]
[9 9 9]
[4 5 6]
[7 8 9]]
Insert a sub-array of "9s" at position 1 in array two along axis 1 (cols):
[[1 9 2 3]
[4 9 5 6]
[7 9 8 9]]
The unique method will return the unique elements along the specified axis. If no axis is provided the unique method will operate over a flattened version of the array. By unique we refer to the unique rows and columns as a whole, not the unique elements within a row or a column.
print(f'Array three:\n{array_three}\n')
print(f'Unique elements flattened version array three:\n{unique_one}\n')
print(f'Unique elements along axis 0 (rows) array three:\n{unique_two}\n')
print(f'Unique elements along axis 1 (cols) array three:\n{unique_three}')
Array three:
[[1 1 2 2]
[1 1 2 2]
[2 2 3 3]
[2 2 3 3]]
Unique elements flattened version array three:
[1 2 3]
Unique elements along axis 0 (rows) array three:
[[1 1 2 2]
[2 2 3 3]]
Unique elements along axis 1 (cols) array three:
[[1 2]
[1 2]
[2 3]
[2 3]]
Rearranging array elements
By rearranging we refer to altering the order or position of the elements of an array without changing its shape (for that see the shape manipulation section).
array_one = np.arange(1,10)
array_two = np.arange(1,10).reshape((3,3))
flip_one, flip_two, flip_three, flip_four = np.flip(array_one), np.flip(array_two), np.flip(array_two, 0), np.flip(array_two, 1)
roll_one, roll_two, roll_three, roll_four = np.roll(array_one, 1), np.roll(array_two, 1), np.roll(array_two, 1, axis=0), np.roll(array_two, 1, axis=1)
The flip reverse the order of elements in an array along the specified axis. If no axis is specified, the order of the elements is reversed as if it were a flattened array, but the shape is preserved. Notice that for arrays with 2 or more axis, flipping happens to entire rows or columns (or elements of the axis) rather than that to elements within rows or columns. There are many ways to flip an array by combining position and axis, here just a couple of examples.
print(f'Array one:\n{array_one}\n')
print(f'Array two:\n{array_two}\n')
print(f'Reverse array one:\n{flip_one}\n')
print(f'Reverse array two:\n{flip_two}\n')
print(f'Reverse array two along axis 0 (rows):\n{flip_three}\n')
print(f'Reverse array two along axis 1 (cols):\n{flip_four}\n')
Array one:
[1 2 3 4 5 6 7 8 9]
Array two:
[[1 2 3]
[4 5 6]
[7 8 9]]
Reverse array one:
[9 8 7 6 5 4 3 2 1]
Reverse array two:
[[9 8 7]
[6 5 4]
[3 2 1]]
Reverse array two along axis 0 (rows):
[[7 8 9]
[4 5 6]
[1 2 3]]
Reverse array two along axis 1 (cols):
[[3 2 1]
[6 5 4]
[9 8 7]]
The roll method moves or “push” elements in an array along the specified axis. This has the effect of moving all elements at once, so all get repositioned. There are many ways to roll an array by combining the number of positions to be roll and the axis, here just a couple of examples.
print(f'Array one:\n{array_one}\n')
print(f'Array two:\n{array_two}\n')
print(f'Roll elements array one by one position:\n{roll_one}\n')
print(f'Roll elements array two by one position:\n{roll_two}\n')
print(f'Roll elements array two by one position along axis 0 (rows):\n{roll_three}\n')
print(f'Roll elements array two by one position along axis 1 (cols):\n{roll_four}')
Array one:
[1 2 3 4 5 6 7 8 9]
Array two:
[[1 2 3]
[4 5 6]
[7 8 9]]
Roll elements array one by one position:
[9 1 2 3 4 5 6 7 8]
Roll elements array two by one position:
[[9 1 2]
[3 4 5]
[6 7 8]]
Roll elements array two by one position along axis 0 (rows):
[[7 8 9]
[1 2 3]
[4 5 6]]
Roll elements array two by one position along axis 1 (cols):
[[3 1 2]
[6 4 5]
[9 7 8]]
Logic functions and array evaluation
There are multiple cases where applying logic functions to evaluate array elements will come in handy. Slicing, indexing, and data transformation rely heavily on logic functions.
NumPy logic functions can be divided on boolean testing, array identity testing, array elements testing, logic operators, and comparison operators.
Boolean testing
Boolean testing refers to whether all or some elements of an array are True. There are two functions for this all and any. Below I exemplify several cases:
true_array = np.array([True, True, True])
some_true_array = np.array([True, False, False])
false_array = np.array([False, False, False])
ones_array = np.ones(3)
some_ones_array = np.array([1, 1, 0])
zeros_array = np.zeros(3)
NAN_array = np.array([np.nan, np.nan, np.nan])
Infinity_array = np.array([np.inf, np.inf, np.inf])
print(f'All elements of true_array are True: {np.all(true_array)}')
print(f'Some elements of true_array are True: {np.any(true_array)}\n')
print(f'All elements of some_true_array are True: {np.all(some_true_array)}')
print(f'Some elements of some_true_array are True: {np.any(some_true_array)}\n')
print(f'All elements of false_array are True: {np.all(false_array)}')
print(f'Some elements of false_array are True: {np.any(false_array)}\n')
print(f'All elements of ones_array are True: {np.all(ones_array)}')
print(f'Some elements of ones_array are True: {np.any(ones_array)}\n')
print(f'All elements of some_ones_array are True: {np.all(some_ones_array)}')
print(f'Some elements of some_ones_array are True: {np.any(some_ones_array)}\n')
print(f'All elements of zeros_array are True: {np.all(zeros_array)}')
print(f'Some elements of zeros_array are True: {np.any(zeros_array)}\n')
print(f'All elements of NAN_array are True: {np.all(NAN_array)}')
print(f'Some elements of NAN_array are True: {np.any(NAN_array)}\n')
print(f'All elements of Infinity_array are True: {np.all(Infinity_array)}')
print(f'Some elements of Infinity_array are True: {np.any(Infinity_array)}\n')
All elements of true_array are True: True
Some elements of true_array are True: True
All elements of some_true_array are True: False
Some elements of some_true_array are True: True
All elements of false_array are True: False
Some elements of false_array are True: False
All elements of ones_array are True: True
Some elements of ones_array are True: True
All elements of some_ones_array are True: False
Some elements of some_ones_array are True: True
All elements of zeros_array are True: False
Some elements of zeros_array are True: False
All elements of NAN_array are True: True
Some elements of NAN_array are True: True
All elements of Infinity_array are True: True
Some elements of Infinity_array are True: True
Array elements testing
This subset of functions tests the identity elements of an array, particularly for NumPy constant like NAN or infinity. This is useful for data cleaning and debugging purposes. Return values are always True or False. Below some examples:
element_testing = [1, 0, np.nan, np.inf, -np.inf,]
print(f'Array to test:\n{element_testing}\n')
print(f'Element-wise testing for finiteness:\n{np.isfinite(element_testing)}\n')
print(f'Element-wise testing for infinity:\n{np.isinf(element_testing)}\n')
print(f'Element-wise testing for negative infinity:\n{np.isneginf(element_testing)}\n')
print(f'Element-wise testing for positive infinity:\n{np.isposinf(element_testing)}\n')
print(f'Element-wise testing for not a number:\n{np.isnan(element_testing)}\n')
Array to test:
[1, 0, nan, inf, -inf]
Element-wise testing for finiteness:
[ True True False False False]
Element-wise testing for infinity:
[False False False True True]
Element-wise testing for negative infinity:
[False False False False True]
Element-wise testing for positive infinity:
[False False False True False]
Element-wise testing for not a number:
[False False True False False]
Notice that np.nan is neither infinity nor finite, simply because is not a number, and only numbers can be tested for that.
Array type testing
Array type testing is another example of element-wise testing but for the specific case of data type. Return values are always True or False. Here are a couple of examples of the available functions:
# use Python list instead of array to mix data types
type_testing = [1+1j, 0, 1, 2.0, False, np.nan, np.inf, 3j]
print(f'Array tested:\n{type_testing}\n')
print(f'Is real:\n{np.isreal(type_testing)}\n')
print(f'Is scalar:\n{np.isreal(type_testing)}\n')
print(f'Is complex:\n{np.iscomplex(type_testing)}\n')
Array tested:
[(1+1j), 0, 1, 2.0, False, nan, inf, 3j]
Is real:
[False True True True True True True False]
Is scalar:
[False True True True True True True False]
Is complex:
[ True False False False False False False True]
Logical operators
Logic operators are a subset of logical functions in NumPy. Basically, the operators you will find in logic gates or Truth tables: and, or, not, xor (exclusive or). Return values are always True or False. Keep in mind that each element of the array is tested independently on both conditions.
array = np.arange(7)
print(f'Array:\n{array}\n')
print(f'Greater than 1 AND less than 5:\n{np.logical_and(array> 1, array<5)}\n')
print(f'Greater than 1 OR less than 5:\n{np.logical_or(array> 1, array<5)}\n')
print(f'Greater than 1 NOT less than 5:\n{np.logical_and(array> 1, array<5)}\n')
print(f'Greater than 1 XOR less than 5:\n{np.logical_xor(array> 1, array<5)}\n')
Array:
[0 1 2 3 4 5 6]
Greater than 1 AND less than 5:
[False False True True True False False]
Greater than 1 OR less than 5:
[ True True True True True True True]
Greater than 1 NOT less than 5:
[False False True True True False False]
Greater than 1 XOR less than 5:
[ True True False False False True True]
Comparison operators
Comparison operators assess the relationship between a pair of arrays or array elements. Given the inaccuracies resulting from the finite or truncated representation of infinite or very large (or small) numbers, a comparison of quantities should proceed with caution. Let’s begin for the greater to illustrate the logic:
array_one = np.array([1, 1, 3])
array_two = np.array([1, 2, 2])
print(f'Element-wise GREATER than comparison:\n{np.greater(array_one, array_two)}\n')
print(f'Element-wise GREATER than comparison shorthand (>):\n{array_one > array_two}\n')
print(f'Element-wise GREATER than comparison (flip):\n{np.greater(array_two, array_one)}\n')
print(f'Element-wise GREATER than comparison shorthand (>) (flip):\n{array_two > array_one}')
Element-wise GREATER than comparison:
[False False True]
Element-wise GREATER than comparison shorthand (>):
[False False True]
Element-wise GREATER than comparison (flip):
[False True False]
Element-wise GREATER than comparison shorthand (>) (flip):
[False True False]
Notice that although we are comparing the same arrays, the order matters. In the first case you are asking: “is 1 greater than 1, is 1 greater than 2, is 3 greater than 2”. Whereas in the second case: “is 1 greater than 1, is 2 greater than 1, is 2 greater than 3”. Also, notice you can use the > shorthand. The same logic applies to the following cases:
print(f'Element-wise GREATER_EQUAL than comparison:\n{np.greater_equal(array_one, array_two)}\n')
print(f'Element-wise GREATER_EQUAL than comparison shorthand (>=):\n{array_one >= array_two}\n')
print(f'Element-wise LESS than comparison:\n{np.less(array_one, array_two)}\n')
print(f'Element-wise LESS than comparison shorthand (<):\n{array_one < array_two}\n')
print(f'Element-wise LESS_EQUAL than comparison:\n{np.less_equal(array_one, array_two)}\n')
print(f'Element-wise LESS_EQUAL than comparison shorthand (<=):\n{array_one <= array_two}\n')
print(f'Element-wise EQUAL than comparison:\n{np.equal(array_one, array_two)}\n')
print(f'Element-wise EQUAL than comparison shorthand (==):\n{array_one == array_two}\n')
print(f'Element-wise NOT_EQUAL than comparison:\n{np.not_equal(array_one, array_two)}\n')
print(f'Element-wise NOT_EQUAL than comparison shorthand (!=):\n{array_one != array_two}\n')
Element-wise GREATER_EQUAL than comparison:
[ True False True]
Element-wise GREATER_EQUAL than comparison shorthand (>=):
[ True False True]
Element-wise LESS than comparison:
[False True False]
Element-wise LESS than comparison shorthand (<):
[False True False]
Element-wise LESS_EQUAL than comparison:
[ True True False]
Element-wise LESS_EQUAL than comparison shorthand (<=):
[ True True False]
Element-wise EQUAL than comparison:
[ True False False]
Element-wise EQUAL than comparison shorthand (==):
[ True False False]
Element-wise NOT_EQUAL than comparison:
[False True True]
Element-wise NOT_EQUAL than comparison shorthand (!=):
[False True True]
Now we review comparison operators which help to deal with cases where you would think two values should be considered equal, but they are not:
array_three = np.array([1e10,1e-8])
array_four = np.array([1.00001e10,1e-9])
print(f"Array three: {array_three}, Array four: {array_four}\n")
print(f"Element-wise equality: {np.equal(array_three, array_four)}")
print(f"Element-wise is close: {np.isclose(array_three,array_four)}")
Array three: [1.e+10 1.e-08], Array four: [1.00001e+10 1.00000e-09]
Element-wise equality: [False False]
Element-wise is close: [ True True]
In the example above both numbers are “practically” the same, but technically they are not. Depending on your task at hand, you may want them to be evaluated as equal (given some tolerance level), and you can use the isclose method for such purpose. Examples of how the evaluation changes as you change the tolerance:
print(f"Element-wise is close: {np.isclose(array_three,array_four, atol=0.0)}")
print(f"Element-wise is close: {np.isclose(array_three,array_four, atol=0.0001)}")
Element-wise is close: [ True False]
Element-wise is close: [ True True]
To compare whether two arrays are equal, this is, if they contain the same elements and have the same shape:
array_five = array_six = np.array([1, 2, 3])
print(f'Are array-three and array-four equal: {np.array_equal(array_three, array_four)}\n')
print(f'Are array-five and array-six equal: {np.array_equal(array_five, array_six)}')
Are array-three and array-four equal: False
Are array-five and array-six equal: True
Array Indexing
Elements in a have indices, which simply are numbers identifying the position each element occupies in the array.
Indexing in NumPy is 0-based, as in native Python, meaning that you start to count positions at 0 rather than at 1. Indexing is done by utilizing square brackets as ([]).
Indexing is a versatile operation useful in a wide variety of cases. The most common ones are to insert (“assignment”) values, to extract (“reference”) values, to delete values, and to change values.
In what follows I refer to operations and objects with concepts that are commonly used in data science, but that deviate a bit from technical indexing terminology in NumPy. For a more technical treatment of the topic see here.
I also mostly use extraction or “reference” kind of operations to illustrate concepts, but the same ideas apply to insert, deleting, or changing values.
Basic indexing in one-dimensional arrays
NumPy support indexing in one and multiple dimensions. Let’s explore a simple case with a couple of examples.
array_one = np.arange(1,11)
print(f'Array one: {array_one}')
print(f'Array one dimensions: {array_one.ndim}, shape:{array_one.shape}')
Array one: [ 1 2 3 4 5 6 7 8 9 10]
Array one dimensions: 1, shape:(10,)
Elements in array are index with square brackets:
print(f'Select element at position [0]: {array_one[0]}')
print(f'Select element at position [5]: {array_one[5]}')
print(f'Select element at position [9]: {array_one[9]}')
print(f'Select element at position [-5]: {array_one[-5]}')
print(f'Select element at position [-1]: {array_one[-1]}')
Select element at position [0]: 1
Select element at position [5]: 6
Select element at position [9]: 10
Select element at position [-5]: 6
Select element at position [-1]: 10
Notice that array_one[9] and array_one[-1] return the same value, which is the last element of the array. This shows that NumPy (as Python does) can index elements both ways: (1) from left-to-right starting at 0, and (2) from right-to-left starting at -1. The image below illustrates NumPy indexing that you can use as a mental model.

Slicing one-dimensional arrays
To select a range of elements, also known as slicing, we use the [:] notation:
print(f'Elements from position [0] to position [3]: {array_one[0:3]}')
print(f'Elements from position [5] to position [9]: {array_one[5:9]}')
print(f'Elements from position [-9] to position [-5]: {array_one[-9:-5]}')
print(f'Elements from position [-3] to position [-1]: {array_one[-3:-1]}')
print(f'Elements from position [3] to position [-1]: {array_one[3:-1]}')
Elements from position [0] to position [3]: [1 2 3]
Elements from position [5] to position [9]: [6 7 8 9]
Elements from position [-9] to position [-5]: [2 3 4 5]
Elements from position [-3] to position [-1]: [8 9]
Elements from position [3] to position [-1]: [4 5 6 7 8 9]
There are a couple of interesting facts here. NumPy operates including the first element on the left but the last on the right. In set notation:
This is why the element at position 3 (i.e., number 4) is not included in array_one[0:3].
It’s also interesting to notice that when using negative indices (right-to-left), you still have to ‘think’ with a left-to-right logic, this is, considering that indices are organized as [-10, -9, -8, …, -3, -2, -1]. You can also ‘mix’ left-to-right and right-to-left indices as in array_one[3:-1].
When we slice arrays to return sub-arrays, we can specify the stride, this is, how many steps we take when pointing at indices to retrieve array elements. The default stride is one. This is simple to see with a couple of examples:
print(f'Slice from position [0] to position [6] with stride [1]: {array_one[0:6:1]}')
print(f'Slice from position [0] to position [6] with stride [2]: {array_one[0:6:2]}')
print(f'Slice from position [-6] to position [-1] with stride [3]: {array_one[-6:-1:3]}')
Slice from position [0] to position [6] with stride [1]: [1 2 3 4 5 6]
Slice from position [0] to position [6] with stride [2]: [1 3 5]
Slice from position [-6] to position [-1] with stride [3]: [5 8]
Basic indexing in multidimensional arrays
Array indexing with multiple dimensions follows the same logic as with one dimension. The NumPy indexing model figure above illustrates this as well.
There are two ways to index arrays with multiple dimensions:
- referencing each dimension/axis within a single pair of square brackets with each dimension/axis separated by commas
[,] - referencing each dimension independently with as many square brackets as dimensions/axes
[][]
Here a couple of examples:
array_two = np.arange(1,10).reshape((3,3))
array_three = np.arange(1,9).reshape((2,2,2))
print(f'Array two dimensions/axes: \n{array_two}\n')
print(f'Array three dimensions/axes: \n{array_three}\n')
print(f'Array two dimensions: {array_two.ndim}, shape:{array_two.shape}')
print(f'Array three dimensions: {array_three.ndim}, shape:{array_three.shape}')
Array two dimensions/axes:
[[1 2 3]
[4 5 6]
[7 8 9]]
Array three dimensions/axes:
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
Array two dimensions: 2, shape:(3, 3)
Array three dimensions: 3, shape:(2, 2, 2)
print(f'Element at position 1 in first axis (rows) and position 1 in second axis (cols): {array_two[1,1]}')
print(f'Element at position 0 in first axis (rows) and position 2 in second axis (cols): {array_two[0,2]}')
print(f'Element at position -1 in first axis (rows) and position -3 in second axis (cols): {array_two[-1,-3]}')
Element at position 1 in first axis (rows) and position 1 in second axis (cols): 5
Element at position 0 in first axis (rows) and position 2 in second axis (cols): 3
Element at position -1 in first axis (rows) and position -3 in second axis (cols): 7
We can retreive the same elements by utilizing the [][] notation as:
print(f'Element at position 1 in first axis (rows) and position 1 in second axis (cols): {array_two[1][1]}')
print(f'Element at position 0 in first axis (rows) and position 2 in second axis (cols): {array_two[0][2]}')
print(f'Element at position -1 in first axis (rows) and position -3 in second axis (cols): {array_two[-1][-3]}')
Element at position 1 in first axis (rows) and position 1 in second axis (cols): 5
Element at position 0 in first axis (rows) and position 2 in second axis (cols): 3
Element at position -1 in first axis (rows) and position -3 in second axis (cols): 7
What notation to use then? If you plan to delete the original array (array_one in this example), you are better of utilizing [][] notation as this creates a new temporary array that occupies memory. Otherwise, you will be better off by utilizing [,] instead as it is only a view, i.e., a pointer to the original array that does not occupy extra memory, so it’s faster.
To index ranges or intervals in multidimensional arrays, we can mix the slice notation [:] with the multidimensional index notation [,].
Selecting elements from the first axis or “row-wise” in two-dimensional arrays:
print(f'Array two as reference: \n{array_two}\n')
print(f'All elements at position 0 from first axis (all elements from first row): \n{array_two[0,:]}\n')
print(f'All elements at position 1 from first axis (all elements from second row): \n{array_two[1,:]}\n')
print(f'All elements at position 2 from first axis (all elements from third row): \n{array_two[2,:]}\n')
Array two as reference:
[[1 2 3]
[4 5 6]
[7 8 9]]
All elements at position 0 from first axis (all elements from first row):
[1 2 3]
All elements at position 1 from first axis (all elements from second row):
[4 5 6]
All elements at position 2 from first axis (all elements from third row):
[7 8 9]
Selecting elements from the second axis or “column-wise” in two-dimensional arrays:
print(f'Array two as reference: \n{array_two}\n')
print(f'All elements at position 0 from second axis (all elements from first column): \n{array_two[:,0]}\n')
print(f'All elements at position 1 from second axis (all elements from second column): \n{array_two[:,1]}\n')
print(f'All elements at position 2 from second axis (all elements from third column): \n{array_two[:,2]}\n')
Array two as reference:
[[1 2 3]
[4 5 6]
[7 8 9]]
All elements at position 0 from second axis (all elements from first column):
[1 4 7]
All elements at position 1 from second axis (all elements from second column):
[2 5 8]
All elements at position 2 from second axis (all elements from third column):
[3 6 9]
Selecting elements ranges of elements in both axes in two dimensional arrays:
print(f'Elements at position 0 and 1 from first axis (rows) and position 0 from second axis (cols): \n{array_two[0:2,0]}\n')
print(f'Elements at position 0 and 1 from first axis (rows) and position 0 and 1 from second axis (cols): \n{array_two[0:2,0:2]}\n')
print(f'Elements at position 1 and 2 from first axis (rows) and position 1 and 2 from second axis (cols): \n{array_two[1:3,1:3]}\n')
Elements at position 0 and 1 from first axis (rows) and position 0 from second axis (cols):
[1 4]
Elements at position 0 and 1 from first axis (rows) and position 0 and 1 from second axis (cols):
[[1 2]
[4 5]]
Elements at position 1 and 2 from first axis (rows) and position 1 and 2 from second axis (cols):
[[5 6]
[8 9]]
As with one dimensional arrays, we can also specify the “stride” to select elements by adding a
print(f'All elements at position 0 from first axis (all elements from first row) with stride 1: \n{array_two[0,::1]}\n')
print(f'All elements at position 0 from first axis (all elements from first row) with stride 2: \n{array_two[0,::2]}\n')
print(f'All elements at position 0 from second axis (all elements from first column) with stride 1: \n{array_two[::1,0]}\n')
print(f'All elements at position 0 from second axis (all elements from first column) with stride 2: \n{array_two[::2,0]}\n')
All elements at position 0 from first axis (all elements from first row) with stride 1:
[1 2 3]
All elements at position 0 from first axis (all elements from first row) with stride 2:
[1 3]
All elements at position 0 from second axis (all elements from first column) with stride 1:
[1 4 7]
All elements at position 0 from second axis (all elements from first column) with stride 2:
[1 7]
To select elements from three-dimensional arrays you follow the same logic. Recall that the axes (2,2,2), represent 2 arrays with 2 rows and 2 columns each. Hence, the second and third axes represent how “height” and “width” of the two-dimensional arrays, whereas the first index how many of those are “stack” together. Below a couple of examples:
print(f'Array three as reference: \n{array_three}\n')
print(f'First two-dimensional array:\n{array_three[0]}\n')
print(f'Second two-dimensional array:\n{array_three[1]}\n')
print(f'All elements at position 0 from first two-dimensional array (first row first array):\n{array_three[0][0,:]}\n')
print(f'All elements at position 1 from second two-dimensional array (second row second array):\n{array_three[1][1,:]}\n')
Array three as reference:
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
First two-dimensional array:
[[1 2]
[3 4]]
Second two-dimensional array:
[[5 6]
[7 8]]
All elements at position 0 from first two-dimensional array (first row first array):
[1 2]
All elements at position 1 from second two-dimensional array (second row second array):
[7 8]
As I mentioned at the beginning of this section, inserting, deleting, and changing values is done with the same logic.
Below a couple of examples inserting constant values:
x = np.arange(10)
print(f'Array x:{x}\n')
x[2] = 33
print(f'Insert a 33 at position 2: {x}\n')
x[6:-1] = 728
print(f'Insert a 728 between positions 6 and -1: {x}')
Array x:[0 1 2 3 4 5 6 7 8 9]
Insert a 33 at position 2: [ 0 1 33 3 4 5 6 7 8 9]
Insert a 728 between positions 6 and -1: [ 0 1 33 3 4 5 728 728 728 9]
You can insert ranges of values or sub-arrays as long as is shape-consistent:
y = np.arange(10)
y[-6:-1] = np.arange(100,105)
print(f'Insert values [100 101 102 103 104] between positions -6 and -1:\n\n{y}')
Insert values [100 101 102 103 104] between positions -6 and -1:
[ 0 1 2 3 100 101 102 103 104 9]
You can change specific values by specifying their index position:
z = np.arange(10)
z[2:5] = z[2:5]*27
print(f'Multiply by 27 values from position [2] to position [5]:\n\n{z}')
Multiply by 27 values from position [2] to position [5]:
[ 0 1 54 81 108 5 6 7 8 9]
Boolean or Mask indexing
Boolean arrays, or arrays made of True and/or False values, can be used to index elements from other arrays. This type of indexing is also known as “mask” indexing. To work, the Boolean array must be of the same shape as the array to be indexed.
Here is a mental image you can use: imagine you have two arrays, one with the numbers from 1 to 10, and a Boolean array with “True” in the even positions and “False” in the odd positions. Now, imagine the squares with “True” are transparent whereas the ones with “False” are opaque. If you overlay the Boolean array on top of the regular array, the numbers in even positions will be visible but not the ones in odd positions. This is analogous to wearing a mask on your face: only the regions with “holes” or transparent will be visible, typically your eyes. This is why (according to me!) Boolean array is called “mask” indexing. The image below exemplifies the process:

array = np.arange(12)
mask = array > 6
print(f'Array: \n{array}\n')
print(f'Mask or Boolean arrayw with "True" for values strictly grater than 6: \n{mask}\n')
print(f'Return an sub-array where "mask" elements are "True": \n{array[mask]}\n')
Array:
[ 0 1 2 3 4 5 6 7 8 9 10 11]
Mask or Boolean arrayw with "True" for values strictly grater than 6:
[False False False False False False False True True True True True]
Return an sub-array where "mask" elements are "True":
[ 7 8 9 10 11]
We can as many conditions to create Boolean arrays as we desire. The syntax is [(firs-condition) & (second-condition) & ... (last-condition)]. For instance, to select elements larger than 1 AND smaller than 5, we do:
print(f'Boolean array with elements larger than 1 and smaller than 5:\n{[(1 < array) & (array < 5)]}\n')
print(f'Select elements larger than 1 and smaller than 5 from 1-12:\n{array[(1 < array) & (array < 5)]}')
Boolean array with elements larger than 1 and smaller than 5:
[array([False, False, True, True, True, False, False, False, False,
False, False, False])]
Select elements larger than 1 and smaller than 5 from 1-12:
[2 3 4]
We can combine multiple logic, comparison, and identity operators to create complex Boolean arrays (see here). For instance:
print(f'Select elements equal to 2 OR larger than 9 :\n{array[(2 == array) | (array > 9)]}\n')
print(f'Select even elements (modulo == 0) OR larger than 9 :\n{array[((array % 2) == 0) | (array > 9)]}\n')
print(f'Select elements that are NOT 2 and NOT 7 and NOT 9 :\n{array[(2 != array) & (array != 7) & (array != 10)]} ')
Select elements equal to 2 OR larger than 9 :
[ 2 10 11]
Select even elements (modulo == 0) OR larger than 9 :
[ 0 2 4 6 8 10 11]
Select elements that are NOT 2 and NOT 7 and NOT 9 :
[ 0 1 3 4 5 6 8 9 11]
This type of indexing comes in handy for conditional selection or modification of array elements. I use it all the time when I need to subset datasets by any attribute(s): people older than 65, income lower than 1,000 and higher than a 100,000, scores in between 50-80, states larger than 5,000 of inhabitants, males with diabetes or chronic kidney disease, and so on.
Boolean indexing in multidimensional arrays is no different. You just need to pay attention to match the dimensionality of the “mask” and the array to be indexed, in at least one of the dimensions. For instance, if you tried to index a two-dimensional array with a one-dimensional boolean array, it won’t work. Same if the array has the same dimensions/axes, but different shape, i.e., numbers of elements along each axis.
array_two = np.arange(1,17).reshape((4,4))
mask_two = array_two > 8
print(f'Two-dimensional array: \n{array_two}\n')
print(f'Mask or Boolean arrayw with "True" for values strictly greater than 8: \n{mask_two}\n')
print(f'Return an sub-array where "mask" elements are "True": \n{array_two[mask_two]}\n')
print(f'Shape new sub-array: {array_two[mask_two].shape}')
Two-dimensional array:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
Mask or Boolean arrayw with "True" for values strictly greater than 8:
[[False False False False]
[False False False False]
[ True True True True]
[ True True True True]]
Return an sub-array where "mask" elements are "True":
[ 9 10 11 12 13 14 15 16]
Shape new sub-array: (8,)
Notice that the returned sub-array was flattened to a one-dimensional array with 8 elements. If you think about it, this makes sense as the “mask” we used to index values was one-dimensional in the first place.
I also mentioned that array shapes need to match in at least one of the dimensions. This means that a (4, 4) array can be indexed by a boolean array that matches its shape in either the first axis (rows), second axis (columns), or both. In practice, this implies we can index an (n , n) array with an (n, n) mask, a (, n) mask, or an (n, ) mask. Otherwise, it won’t work. Let’s see some examples:
mask_three = np.array([True, False, False, True])
mask_four = np.array([False, True, True, False])
print(f'Two-dimensional array: \n{array_two}\n')
print(f'Select elements at position 1 and 4 along the first axis (first and last rows): \n{array_two[mask_three]}\n')
print(f'Select elements at position 2 and 3 along the second axis (second and third cols): \n{array_two[:,mask_four]}\n')
Two-dimensional array:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
Select elements at position 1 and 4 along the first axis (first and last rows):
[[ 1 2 3 4]
[13 14 15 16]]
Select elements at position 2 and 3 along the second axis (second and third cols):
[[ 2 3]
[ 6 7]
[10 11]
[14 15]]
Indexing-like NumPy functions
There are several NumPy functions design to reference or extract elements in arrays (see here). In general, these are things you can accomplish with basic indexing notation, but that can get pretty complicated to craft.
The take function will “take” elements along some axis given some indices. It’s simply like pointing and choosing: “hey, I want elements at positions 0, 2 -1 from the rows (or cols, or flattened array)”.
print(f'One-dimensional array:\n{array}\n')
print(f'Two-dimensional array:\n{array_two}\n')
# take
indices = [0, 2, -1]
print(f'Take elements at positions 0, 2 and -1 from one-dim array:\n{np.take(array, indices)}\n')
print(f'Take elements at positions 0, 2 and -1 from one-dim array along the first (row) axis:\n{np.take(array_two, indices, axis=0)}\n')
print(f'Take elements at positions 0, 2 and -1 from one-dim array along the second (col) axis:\n{np.take(array_two, indices, axis=1)}\n')
One-dimensional array:
[ 0 1 2 3 4 5 6 7 8 9 10 11]
Two-dimensional array:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
Take elements at positions 0, 2 and -1 from one-dim array:
[ 0 2 11]
Take elements at positions 0, 2 and -1 from one-dim array along the first (row) axis:
[[ 1 2 3 4]
[ 9 10 11 12]
[13 14 15 16]]
Take elements at positions 0, 2 and -1 from one-dim array along the second (col) axis:
[[ 1 3 4]
[ 5 7 8]
[ 9 11 12]
[13 15 16]]
The choose function will return an array given a set of indices and arrays to choose from. The logic’s a bit more complicated. It’s similar to ordering food in a restaurant from different types of food: “The first element of my new array will be the first element of array 3, the second element will be the second element from array 1, the third element will be the third element from array 2, and the fourth element will be the fourth element from array 0”.
The mechanics are always the same. The flexibility comes from deciding the order from which array you extract elements. This allows for complex indexing like “diagonals” and “staircase”.
# choose
choices_one = [3, 1, 2, 0]
choices_diagonal = [0, 1, 2, 3]
choices_diagonal_back = [3, 2, 1, 0]
print(f'Two-dimensional array:\n{array_two}\n')
print(f'Choose the 1st element from the 4th array, the 2nd from the 1st, the 3th from the 2nd, and the 4th from the 1st: \n{np.choose(choices_one, array_two)}\n')
print(f'Choose diagonal elements from top-left to botton-right: \n{np.choose(choices_diagonal, array_two)}\n')
print(f'Choose diagonal elements from bottom-left to top-right: \n{np.choose(choices_diagonal_back, array_two)}\n')
Two-dimensional array:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
Choose the 1st element from the 4th array, the 2nd from the 1st, the 3th from the 2nd, and the 4th from the 1st:
[13 6 11 4]
Choose diagonal elements from top-left to botton-right:
[ 1 6 11 16]
Choose diagonal elements from bottom-left to top-right:
[13 10 7 4]
A simpler and more flexible way to extract diagonals is with the diagonal function:
print(f'Two-dimensional array:\n{array_two}\n')
print(f'Extract 1st-diagonal diagonal elements from top-left to bottom-right: \n{np.diagonal(array_two, offset=0)}\n')
print(f'Extract 2st-diagonal diagonal elements from top-left to bottom-right: \n{np.diagonal(array_two, offset=1)}\n')
print(f'Extract 3st-diagonal diagonal elements from top-left to bottom-right: \n{np.diagonal(array_two, offset=2)}\n')
Two-dimensional array:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
Extract 1st-diagonal diagonal elements from top-left to bottom-right:
[ 1 6 11 16]
Extract 2st-diagonal diagonal elements from top-left to bottom-right:
[ 2 7 12]
Extract 3st-diagonal diagonal elements from top-left to bottom-right:
[3 8]
To extract the diagonals in the opposite direction, from bottom-right to the top-left, you have to flip the array vertically and then horizontally.
print(f'Two-dimensional array\n{array_two}\n')
print(f'Vertical flip: \n{np.flipud(array_two)}\n')
print(f'Horizontal flip: \n{np.fliplr(array_two)}\n')
print(f'Vertical and horizontal flip: \n{np.fliplr(np.flipud(array_two))}\n')
print(f'Extract 1st-diagonal diagonal from bottom-right to top-left: \n{np.diagonal(np.fliplr(np.flipud(array_two)), offset=0)}\n')
print(f'Extract 2st-diagonal diagonal from bottom-right to top-left: \n{np.diagonal(np.fliplr(np.flipud(array_two)), offset=1)}\n')
print(f'Extract 3st-diagonal diagonal from bottom-right to top-left: \n{np.diagonal(np.fliplr(np.flipud(array_two)), offset=2)}\n')
Two-dimensional array
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
Vertical flip:
[[13 14 15 16]
[ 9 10 11 12]
[ 5 6 7 8]
[ 1 2 3 4]]
Horizontal flip:
[[ 4 3 2 1]
[ 8 7 6 5]
[12 11 10 9]
[16 15 14 13]]
Vertical and horizontal flip:
[[16 15 14 13]
[12 11 10 9]
[ 8 7 6 5]
[ 4 3 2 1]]
Extract 1st-diagonal diagonal from bottom-right to top-left:
[16 11 6 1]
Extract 2st-diagonal diagonal from bottom-right to top-left:
[15 10 5]
Extract 3st-diagonal diagonal from bottom-right to top-left:
[14 9]
To obtain the opposite diagonal or “anti-diagonal” from the top-right to the bottom-left (and its reverse):
print(f'Two-dimensional array: \n{array_two}\n')
print(f'Antidiagonal: \n{np.diagonal(np.fliplr(array_two), offset=0)}\n')
print(f'Antidiagonal from bottom-left to top-right: \n{np.diagonal(np.flipud(array_two), offset=0)}\n')
Two-dimensional array:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
Antidiagonal:
[ 4 7 10 13]
Antidiagonal from bottom-left to top-right:
[13 10 7 4]
The select function allows for combining multiple conditions to choose elements from multiple arrays. The output will be the elements where the conditions are evaluated as True, and the rest will be set to 0 or to a user-defined default value.
x = np.arange(10)
y = np.arange(1,11)
condlist = [x<3, x>5]
choicelist = [x, y]
print(f'Select elements from x where x<3, and elements from y where x>5: \n{np.select(condlist, choicelist)}\n')
print(f'Select elements from x where x<3, and elements from y where x>5, with default value 99 for False: \n{np.select(condlist, choicelist, default=99)}\n')
Select elements from x where x<3, and elements from y where x>5:
[ 0 1 2 0 0 0 7 8 9 10]
Select elements from x where x<3, and elements from y where x>5, with default value 99 for False:
[ 0 1 2 99 99 99 7 8 9 10]
If you want to return only the values where a condition is True, a simple approach is to subset the array to the non-zero values as (or any value you defined as default):
non_zero = np.select(condlist, choicelist)
non_nine = np.select(condlist, choicelist, default=99)
print(f'Select non-zero value: \n{non_zero[non_zero != 0]}\n')
print(f'Select non-ninety-nine values (This option prevents you to remove zeros when zero is a valid value):\n{non_nine[non_nine != 99]}')
Select non-zero value:
[ 1 2 7 8 9 10]
Select non-ninety-nine values (This option prevents you to remove zeros when zero is a valid value):
[ 0 1 2 7 8 9 10]
Array iteration
Iterating over arrays refers to the operation of “visiting” elements of an array in a systematic fashion. To iterate over array elements we utilize standard Python syntax (for and while loops) plus the functionality provided by the nditer iterator object.
“OK, so iteration is looping. Wasn’t looping bad though?” Right, I said that. Although is true that you want to avoid explicit Python loops as the plague, there are circumstances where iteration is unavoidable, so you better learn how to do it properly.
I’ll say upfront that array iteration can be a very complex topic. I rarely have had to use this functionality as most libraries will take care of these issues for you. Here I’ll just cover the most basics topics related to array iteration in NumPy you have a good enough notion of what is going on and what are your options.
Basic array iteration
Here is an example of the most basic operation you can do: iterate over array elements one by one.
array = np.arange(1,10).reshape(3,3)
print(f"Two-dimensional array:\n{array}\n")
for element in np.nditer(array):
print(element, end=' ')
Two-dimensional array:
[[1 2 3]
[4 5 6]
[7 8 9]]
1 2 3 4 5 6 7 8 9
There is a technical detail you should be aware of: the nditer object iterates over the array matching the way on which the data is stored in memory. This means that regardless of how you “present” the array to the iterator, you will get back the elements in the same order. This done simply because is faster. For instance:
print(f"Transposed (along main diagonal) two-dimensional array:\n{array.T}\n")
for element in np.nditer(array.T):
print(element, end=' ')
Transposed (along main diagonal) two-dimensional array:
[[1 4 7]
[2 5 8]
[3 6 9]]
1 2 3 4 5 6 7 8 9
If you were expecting to get back 1, 4, 7, 2, 5, 8, 3, 6, 9, you are not alone. I was expecting that order too. But that is not the order data is stored in memory. To visit the elements in the order you would expect by looking at the array, you have to explicitly add you want the C order:
print(f"Transposed (along main diagonal) two-dimensional array:\n{array.T}\n")
for element in np.nditer(array.T.copy(order='C')):
print(element, end=' ')
Transposed (along main diagonal) two-dimensional array:
[[1 4 7]
[2 5 8]
[3 6 9]]
1 4 7 2 5 8 3 6 9
There may be times when you want to update the values of an array while iterating. For instance, reinforcement learning models constantly update values after each iteration. The default behavior of nditer is “read-only”, meaning it won’t let you change values. Hence, you have to specify either “readwrite” or “writeonly” options to update values. Additionally, you have to signal to nditer when you have finished iterating over values, as nditer needs to update the array with the new values. This happens because nditer first save the updated values in a temporary memory space instead of changing values “on the fly”. According to NumPy docs, there are two ways to do this:
- using
nditeras a context manager utilizing the Pythonwithstatement - calling the iterator’s
closemethod at the end of the iteration process
Let’s see an example:
array_to_update = np.arange(1,10).reshape(3,3)
print(f'Array to update:\n{array_to_update}\n')
with np.nditer(array_to_update, op_flags=['readwrite']) as iterator:
for element in iterator:
element[...] = element**2
print(f'Updated array (squared):\n{array_to_update}')
Array to update:
[[1 2 3]
[4 5 6]
[7 8 9]]
Updated array (squared):
[[ 1 4 9]
[16 25 36]
[49 64 81]]
Although looping is not completely avoidable while iterating, there is a way to speed up iteration by partially vectorizing the innermost loop of the iteration. The details of how this work is not relevant from an applied perspective. What you want to know is that it will be faster and that you have to declare the external_loop flag in the iterator. Let’s time both approaches:
%%timeit
large_array = np.arange(10000)
for element in np.nditer(large_array):
element*2
10.3 ms ± 107 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%%timeit
large_array = np.arange(10000)
for element in np.nditer(large_array, flags=['external_loop']):
element*2
12.6 µs ± 51.2 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
By utilizing an external loop, we increased the speed for a factor of around 816 times (0.0125 ms vs 10.2 ms). Not all operations will gain so much on speed, but in general, you will get large gains.
Broadcasting array iteration
If you find yourself having to iterate over multiple arrays with different shapes and dimensionality, the nditer object is smart enough to apply broadcast rules during iteration. For instance:
one_dim_array = np.arange(3)
two_dim_array = np.arange(9).reshape(3,3)
for x, y in np.nditer([one_dim_array, two_dim_array]):
print(f'x: {x}, y:{y}')
x: 0, y:0
x: 1, y:1
x: 2, y:2
x: 0, y:3
x: 1, y:4
x: 2, y:5
x: 0, y:6
x: 1, y:7
x: 2, y:8
Here we can see that nditer broadcast the one_dim_array to match the two_dim_array so iteration does not break.
Allocating outputs from iteration
There are cases where you want to create a function utilizing the nditer object. This is, functions that take an array as input, iterate over the array elements, and instead of modifying the original array, they return the output somewhere else. Here is a basic example I took from the NumPy docs:
def square(a):
with np.nditer([a, None]) as it:
for x, y in it:
y[...] = x*x
return it.operands[1]
input_array = np.arange(1,6)
print(f'Input array: {input_array}')
print(f'Input array squared: {square(input_array)}')
Input array: [1 2 3 4 5]
Input array squared: [ 1 4 9 16 25]
Iteration functions
There are a couple of additional functions in NumPy in addition to the nditer object that you can check here. An example is the ndenumerate that returns both the coordinate index values for each element in the array, plus the element itself:
array = np.arange(1,10).reshape(3,3)
for index, element in np.ndenumerate(array):
print(f'Pair of indices: {index}, Element: {element}')
Pair of indices: (0, 0), Element: 1
Pair of indices: (0, 1), Element: 2
Pair of indices: (0, 2), Element: 3
Pair of indices: (1, 0), Element: 4
Pair of indices: (1, 1), Element: 5
Pair of indices: (1, 2), Element: 6
Pair of indices: (2, 0), Element: 7
Pair of indices: (2, 1), Element: 8
Pair of indices: (2, 2), Element: 9
Array shallow and deep copies
To copy an array in NumPy can mean three different things:
- To put a new label
- To create a “view” or “shallow copy” that refers to the same chunk of data in memory
- To create an independent or “deep copy” of the array in a different location in memory
Creating “shallow copies” instead of “deep copies” can significantly speed up computation and save space, but it has limitations to keep in mind. The figure below illustrates the differences between the three alternatives.
Let’s examine each case.

Array new label
There are cases where no copy at all is created. All that is done is attaching a new label to the original array. We can use the is and may_share_memory methods to check object identity and memory sharing.
array_one = np.ones(10)
array_two = array_one
print(f'Array one:{array_one}\n')
print(f'Array two:{array_two}\n')
print(f'Are array-one and array-two the same object?: {array_two is array_one}\n')
print(f'Do array-one and array-two share memory?: {np.may_share_memory(array_one, array_two)}')
Array one:[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
Array two:[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
Are array-one and array-two the same object?: True
Do array-one and array-two share memory?: True
The key here is that array_one and array_two share memory AND are the same object.
A logical consequence of the fact that array_one and array_two share the same data and identity, is that if you change array_two you will be inadvertently changing array_one as well:
array_two[-1] = 99
print(f'New array-two:\n{array_two}\n')
print(f'Array-one is changed although no explicit operation was done to it:\n{array_one}')
New array-two:
[ 1. 1. 1. 1. 1. 1. 1. 1. 1. 99.]
Array-one is changed although no explicit operation was done to it:
[ 1. 1. 1. 1. 1. 1. 1. 1. 1. 99.]
If you want two independent copies of the same data, you need a “deep copy” (more on that below).
Array shallow copy or view
“Shallow copies” or “views” are objects which are not the same, but share the same data source. For instance:
array_three = array_one[0:6]
print(f'Array one:{array_one}\n')
print(f'Array three:{array_three}\n')
print(f'Are array-one and array-three the same object?: {array_two is array_three}\n')
print(f'Do array-one and array-three share memory?: {np.may_share_memory(array_one, array_three)}')
Array one:[ 1. 1. 1. 1. 1. 1. 1. 1. 1. 99.]
Array three:[1. 1. 1. 1. 1. 1.]
Are array-one and array-three the same object?: False
Do array-one and array-three share memory?: True
The key here is that array_one and array_three are NOT the same object BUT share memory.
The effect of shallow copies in the base-data is a bit trickier. There are cases where changing a view does not change the base-data, as reshaping:
array_three_reshape = array_three.reshape(2,3)
print(f'Array-three change shape:\n{array_three_reshape}\n')
print(f'But this does not change array-two (the source):\n{array_two}')
Array-three change shape:
[[1. 1. 1.]
[1. 1. 1.]]
But this does not change array-two (the source):
[ 1. 1. 1. 1. 1. 1. 1. 1. 1. 99.]
And cases where it does change the original base-data, as inserting new values:
array_three[0] = 99
print(f'Array-three new value at position 0:\n{array_three}\n')
print(f'This does change array-two (the source):\n{array_two}')
Array-three new value at position 0:
[99. 1. 1. 1. 1. 1.]
This does change array-two (the source):
[99. 1. 1. 1. 1. 1. 1. 1. 1. 99.]
Array deep copy
“Deep copies” are independent copies located in a different position in memory. For instance:
array_four = array_one[0:5].copy()
print(f'Array one:{array_one}\n')
print(f'Array four:{array_four}\n')
print(f'Are array-one and array-four the same object?: {array_one is array_four}\n')
print(f'Do array-one and array-four share memory?: {np.may_share_memory(array_one, array_four)}')
Array one:[99. 1. 1. 1. 1. 1. 1. 1. 1. 99.]
Array four:[99. 1. 1. 1. 1.]
Are array-one and array-four the same object?: False
Do array-one and array-four share memory?: False
The key here is that array_one and array_four NEITHER are the same object NOR share memory.
In this case, there is no way to affect array_one (the base) by changing array_four:
array_four[3] = 99
print(f'Array-four new value at position 3:\n{array_four}\n')
print(f'This does NOT change array-one (the source):\n{array_one}')
Array-four new value at position 3:
[99. 1. 1. 99. 1.]
This does NOT change array-one (the source):
[99. 1. 1. 1. 1. 1. 1. 1. 1. 99.]
Deep copies are recommended when you want to keep a subset of the data and throw away the base array, or when you need to manipulate two or more copies of the same data independently.
Structured arrays
My only goal introducing structured arrays is to advise to not use them unless you need to interface with C code or to do low-level manipulation of structured buffers (As recommended in the NumPy docs). If you need to do such kinds of things you are probably a very advance NumPy user or developer, i.e., you won’t read this anyway.
Let’s look at what structured arrays are:
structured_array = np.array([("Bulbasaur", "Grass", 15.2, 71.12),
("Charmander ", "Fire", 18.7, 60.96)],
dtype=[("Name", 'U10'),
("Type", 'U10'),
("Weight", 'f4'),
("Height", 'f4')])
print(f'Structured array:\n{structured_array}\n')
print(f'First element structured array:\n{structured_array[0]}\n')
print(f'Second element structured array:\n{structured_array[1]}')
Structured array:
[('Bulbasaur', 'Grass', 15.2, 71.12) ('Charmander', 'Fire', 18.7, 60.96)]
First element structured array:
('Bulbasaur', 'Grass', 15.2, 71.12)
Second element structured array:
('Charmander', 'Fire', 18.7, 60.96)
From the example you can gather than structured arrays are n-dimensional arrays composed of mixed data types with named fields. For instance, the first element has four fields: a string for “Name”, a string for “Type”, a float for “Weight”, and a float for “height”. Essentially, the kind of data you would find in a CSV file or a relational database.
What to use then if not structured arrays? Pandas, just use 🐼 which is specifically designed to deal with table-like datasets with mixed data types. Alternatives are xarray and or query languages like PostgreSQL.
Random number generation and sampling with NumPy
Here is an example of something that happened to me: I wrote an on-line book introducing neural network models of cognition. While creating examples, I often had to generate random numbers, particularly to initialize the weights of the network. They were cases where sampling from a uniform random distribution vs random normal distribution was the difference between a model solving the problem and not solving it at all. As you can imagine, knowing how to work with NumPy random generator capabilities is crucial to get such kind of issues right.
Random sampling updated
This or may not be a surprise to you, but Numpy does not actually generate random numbers but pseudo-random numbers basically because generating random numbers is impossible. Just trying out, you won’t be able to, because you will always depend on picking some non-random event to generate the sequence. But worry not: for all practical purposes, NumPy random number generator is “random enough” such that you can use it as if it were “truly random”.
NumPy random generator capabilities were updated on version 1.17.0, meaning that you will probably found outdated ways to use the random number generator online, something like:
from numpy import random
random_numbers = random.standard_normal(10)
According to NumPy documentation, this is not the recommended way. To generate a sequence of random numbers sampled from a standard normal distribution use:
from numpy.random import default_rng
rng = default_rng()
random_numbers = rng.standard_normal(5)
print(f'Random numbers sequence sampled from a normal distributon:\n{random_numbers}')
Random numbers sequence sampled from a normal distributon:
[ 1.28412127 -0.59084961 1.19645635 -1.43902792 -1.16416342]
To explore the difference between the “old” and “new way” to generate random numbers in NumPy see here.
Basic random sampling
The three main methods to generate random numbers are integers, random, and choice. The first generates random integers, the second floats, and the third a uniform random sample from a one-dimensional array. Let’s see them in action.
For the integers method, you need to pass at least one argument indicating the ceiling to be considered:
print(f'A random integer between [1, 10) (10 non-inclusive): \n{rng.integers(10)}\n')
print(f'5 random integers between [1, 10) (10 non-inclusive): \n{rng.integers(10, size=5)}\n\n')
A random integer between [1, 10) (10 non-inclusive):
8
5 random integers between [1, 10) (10 non-inclusive):
[9 3 3 5 8]
The random method is more flexible, as it allows to specify a tuple with the shape of the expected array of random numbers:
print(f'A random float between [0.0, 1.0) (1.0 non-inclusive): \n{rng.random()}\n')
print(f'3 random floats between [0.0, 1.0) (1.0 non-inclusive): \n{rng.random((3,))}\n')
print(f'3,3 random floats between [0.0, 1.0) (1.0 non-inclusive): \n{rng.random((3,3))}\n')
print(f'3,3,3 random floats between [0.0, 1.0) (1.0 non-inclusive): \n{rng.random((3,3,3))}\n')
A random float between [0.0, 1.0) (1.0 non-inclusive):
0.6419758158608625
3 random floats between [0.0, 1.0) (1.0 non-inclusive):
[0.42937336 0.52477446 0.02976526]
3,3 random floats between [0.0, 1.0) (1.0 non-inclusive):
[[0.3604225 0.88741889 0.07464158]
[0.36458258 0.75476422 0.26216883]
[0.69558381 0.49518423 0.77079096]]
3,3,3 random floats between [0.0, 1.0) (1.0 non-inclusive):
[[[0.23506917 0.38961231 0.07247969]
[0.16011855 0.7030183 0.86692858]
[0.00326837 0.34421767 0.05739803]]
[[0.05635481 0.38558642 0.86025178]
[0.83572317 0.96456634 0.28242747]
[0.35763072 0.81671697 0.62012315]]
[[0.5108489 0.65798614 0.07344178]
[0.89918787 0.8241409 0.30456018]
[0.96989985 0.55320836 0.61100954]]]
The choice method needs a one-dimensional array as argument to work:
print(f'A random number from an array [1, 10] (inclusive): \n{rng.choice(np.arange(10))}\n')
print(f'5 random numbers from an array [1, 10] (inclusive): \n{rng.choice(np.arange(10), 5)}\n\n')
A random number from an array [1, 10] (inclusive):
1
5 random numbers from an array [1, 10] (inclusive):
[2 7 2 1 6]
There are a couple of additional options for the choice method to keep in mind:
print("The 'p=' argument indicates the weight for each element of the sample space")
print(f'A non-uniform sample of random numbers from an array [1, 10] (inclusive): \n{rng.choice(np.arange(10), 5, p=[0.1, 0, 0, 0.1, 0, 0.1, 0.2, 0, 0, 0.5])}\n\n')
print("The previous examples were sampling with replacement. We can sample without replacement as well:")
print(f'Uniform sample of random numbers from an array [1, 10] (inclusive): \n{rng.choice(np.arange(10), 5, replace=False)}\n\n')
The 'p=' argument indicates the weight for each element of the sample space
A non-uniform sample of random numbers from an array [1, 10] (inclusive):
[9 9 3 3 3]
The previous examples were sampling with replacement. We can sample without replacement as well:
Uniform sample of random numbers from an array [1, 10] (inclusive):
[2 8 3 6 9]
Setting a seed for reproducibility
In the previous examples, there is no way to reproduce the numbers we generated because we didn’t specify a “seed”. “Wait, we are generating random numbers, why on earth I would want to repeat the same random number?”. To allow others to reproduce your results. In Data Science and Machine Learning different starting points (seeds) may lead to widely different results. There is a joke going around the Internet saying that the “seed” of a random number generator is another parameter of the model to be adjusted, and indeed, it is.
Setting a seed for generating reproducible random numbers is simple:
from numpy.random import default_rng
rg = default_rng(seed=9320)
print(f'{rg.integers(5, size=5)}')
print(f'{rg.integers(5, size=5)}')
print(f'{rg.integers(5, size=5)}')
[0 2 1 0 4]
[2 2 2 3 1]
[3 1 1 0 1]
Now, to get the same sequence of random integers, we just need to use the same seed:
rg = default_rng(seed=9320)
print("Numbers are the same as in the example above:")
print(f'{rg.integers(5, size=5)}')
print(f'{rg.integers(5, size=5)}')
print(f'{rg.integers(5, size=5)}')
Numbers are the same as in the example above:
[0 2 1 0 4]
[2 2 2 3 1]
[3 1 1 0 1]
If you don’t set the seed, you will get different values after every run:
rg = default_rng()
print("This time numbers will change at random:")
print(f'{rg.integers(5, size=5)}')
print(f'{rg.integers(5, size=5)}')
print(f'{rg.integers(5, size=5)}')
This time numbers will change at random:
[4 1 4 0 1]
[0 3 3 2 0]
[3 2 4 4 2]
Again:
rg = default_rng()
print(f'{rg.integers(5, size=5)}')
print(f'{rg.integers(5, size=5)}')
print(f'{rg.integers(5, size=5)}')
[1 0 3 4 4]
[3 0 1 3 4]
[4 0 3 3 3]
Sampling from particular distributions
If you are familiar with probability theory and statistics, you probably know you can sample at random from a wide variety of distributions other than uniform and normal. Luckily, NumPy provides many options to chose from (37 last time I check!). I’ll just illustrate a couple, so check the documentation here to learn more about the other options.
import matplotlib.pylab as plt
plt.style.use('dark_background')
%config InlineBackend.figure_format = 'retina' # to get high resolution images
Sampling from a binomial distribution example:
n, p1, p2, t = 1, .5, .8, 1000
binomial_fair = rg.binomial(n, p1, t)
binomial_bias = rg.binomial(n, p2, t)
fig, (ax1, ax2) = plt.subplots(1, 2, constrained_layout=True)
fig.suptitle('Sampling from binomial distribution')
ax1.hist(binomial_fair)
ax1.set_title("50/50 chance")
ax2.hist(binomial_bias)
ax2.set_title("20/80 chance");
Sampling from a chisquare distribution example:
chisquare1 = rg.chisquare(5,1000)
chisquare2 = rg.chisquare(50,1000)
fig, (ax1, ax2) = plt.subplots(1, 2, constrained_layout=True)
fig.suptitle('Sampling from chisquare distribution')
ax1.hist(chisquare1, bins=50)
ax1.set_title("5 degrees of freedom")
ax2.hist(chisquare2, bins=50)
ax2.set_title("50 degrees of freedom");
Sampling from a poisson distribution example:
poisson1 = rg.poisson(5, 1000)
poisson2 = rg.poisson(50, 1000)
fig, (ax1, ax2) = plt.subplots(1, 2, constrained_layout=True)
fig.suptitle('Sampling from poisson distribution')
ax1.hist(poisson1, bins=10)
ax1.set_title("Expectation of interval: 5")
ax2.hist(poisson2, bins=10)
ax2.set_title("Expectation of interval: 50");
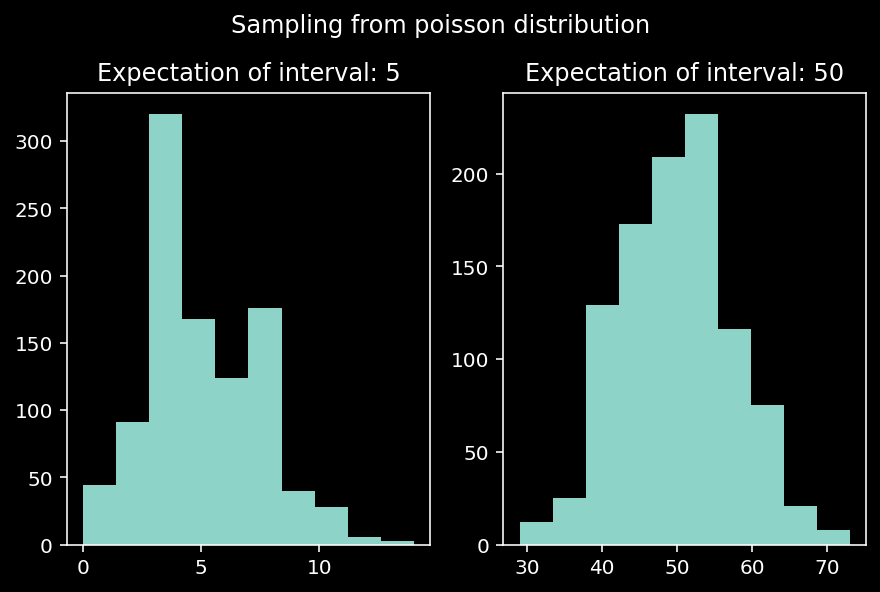
Basic statistics with NumPy
Although NumPy is not a library for statistical analysis, it does provide several descriptive statistics functions. In NumPy documentation these are presented as “order”, “average and variances”, “correlating” and “histograms”, but all of those are just descriptive statistics. Also, keep in mind that pretty much any statistical package in Python you’d find around is based in NumPy as its “engine” anyways.
There are just too many statistical functions to explore them all (see here), so I’ll focus my attention on the most common ones.
Measures of central tendency
Measures of central tendency are indicators of the center or typical value of data distributions. Let’s check the most common ones:
print(f'Arithmetic mean (or simply mean) of poisson distribution: {np.mean(poisson1)}')
print(f'Arithmetic mean (or simply mean) of chisquare distribution: {np.mean(chisquare1)}\n')
print(f'Median of poisson distribution: {np.median(poisson1)}')
print(f'Median of chisquare distribution: {np.median(chisquare1)}\n')
print(f'Weighted average of poisson distribution: {np.average(poisson1, weights=np.flip(poisson1))}')
print(f'Weighted average of chisquare distribution: {np.average(chisquare1, weights=np.flip(chisquare1))}')
Arithmetic mean (or simply mean) of poisson distribution: 5.015
Arithmetic mean (or simply mean) of chisquare distribution: 4.89668496863773
Median of poisson distribution: 5.0
Median of chisquare distribution: 4.212365231904483
Weighted average of poisson distribution: 5.030109670987039
Weighted average of chisquare distribution: 4.931798987029843
Measures of dispersion
Measures of dispersion are indicators of the extent to which data distributions are stretched or squeezed. Let’s check the most common ones:
print(f'Standard deviation of poisson distribution: {np.std(poisson1)}')
print(f'Standard deviation of chisquare distribution: {np.std(chisquare1)}\n')
print(f'Variance of poisson distribution: {np.var(poisson1)}')
print(f'Variance of chisquare distribution: {np.var(chisquare1)}\n')
print(f'Range of values of poisson distribution: {np.ptp(poisson1)}')
print(f'Range of values of chisquare distribution: {np.ptp(chisquare1)}\n')
print(f'Min and max of poisson distribution: {np.amin(poisson1), np.amax(poisson1)}')
print(f'Min and max of chisquare distribution: {np.amin(chisquare1), np.amax(poisson1)}\n')
print(f'Percentile 50th of poisson distribution: {np.percentile(poisson1, 50)}')
print(f'Percentile 50th of chisquare distribution: {np.percentile(chisquare1, 50)}\n')
Standard deviation of poisson distribution: 2.322665494641878
Standard deviation of chisquare distribution: 3.2006656960017534
Variance of poisson distribution: 5.394774999999999
Variance of chisquare distribution: 10.24426089756239
Range of values of poisson distribution: 14
Range of values of chisquare distribution: 23.067229474073194
Min and max of poisson distribution: (0, 14)
Min and max of chisquare distribution: (0.15474240923106727, 14)
Percentile 50th of poisson distribution: 5.0
Percentile 50th of chisquare distribution: 4.212365231904483
Meausres of correlation
Measures of correlation are indicators of the extent and how two or more variables are related to each other (regardless of causality). Let’s check the most common ones:
rand_matrix = np.random.rand(5,5)
print(f"Pearson product-moment correlation coefficient:\n{np.corrcoef(poisson1,poisson2)}\n")
print(f"Cross-correlation coefficient:\n{np.correlate(poisson1,poisson2)}\n")
print(f"Covariance matrix coefficients:\n{np.cov(poisson1,poisson2)}\n")
print(f"Pearson product-moment correlation coefficient:\n{np.corrcoef(rand_matrix)}\n")
print(f"Covariance matrix coefficients:\n{np.cov(rand_matrix)}")
Pearson product-moment correlation coefficient:
[[ 1. -0.03087462]
[-0.03087462 1. ]]
Cross-correlation coefficient:
[249451]
Covariance matrix coefficients:
[[ 5.40017518 -0.53725726]
[-0.53725726 56.07296897]]
Pearson product-moment correlation coefficient:
[[ 1. -0.91426916 -0.37348227 0.47770458 -0.17469488]
[-0.91426916 1. 0.34706955 -0.63275776 -0.14893734]
[-0.37348227 0.34706955 1. -0.80069146 -0.14583296]
[ 0.47770458 -0.63275776 -0.80069146 1. 0.61109471]
[-0.17469488 -0.14893734 -0.14583296 0.61109471 1. ]]
Covariance matrix coefficients:
[[ 0.08273057 -0.04727347 -0.03477924 0.04340413 -0.01916139]
[-0.04727347 0.03231623 0.02019965 -0.03593242 -0.01021005]
[-0.03477924 0.02019965 0.10481758 -0.08188813 -0.01800473]
[ 0.04340413 -0.03593242 -0.08188813 0.09978777 0.07361411]
[-0.01916139 -0.01021005 -0.01800473 0.07361411 0.14542122]]
Histograms
Finally, NumPy also offers some convinient functions to compute histograms:
print(f"Histogram poisson distribution:\n{np.histogram(poisson1)}\n")
print(f"Histogram chisquare distribution:\n{np.histogram(chisquare1)}\n")
print(f"Histogram poisson distribution with 4 bins:\n{np.histogram(poisson1, bins=np.arange(4))}\n")
print(f"Histogram chisquare distribution with 4 bins:\n{np.histogram(chisquare1, bins=np.arange(4))}\n")
Histogram poisson distribution:
(array([ 44, 91, 320, 168, 124, 176, 40, 28, 6, 3]), array([ 0. , 1.4, 2.8, 4.2, 5.6, 7. , 8.4, 9.8, 11.2, 12.6, 14. ]))
Histogram chisquare distribution:
(array([243, 329, 212, 128, 53, 20, 10, 1, 2, 2]), array([ 0.15474241, 2.46146536, 4.7681883 , 7.07491125, 9.3816342 ,
11.68835715, 13.99508009, 16.30180304, 18.60852599, 20.91524894,
23.22197188]))
Histogram poisson distribution with 4 bins:
(array([ 11, 33, 215]), array([0, 1, 2, 3]))
Histogram chisquare distribution with 4 bins:
(array([ 41, 129, 153]), array([0, 1, 2, 3]))
Basic linear algebra with NumPy
Linear algebra is a subject where NumPy shines as an array-like numerical computing library. Much of machine learning and data science is applied linear algebra and NumPy is the (for the most part) perfect tool for that. Since I already wrote a ~20,000 article on linear algebra with NumPy and Python (check it out here) I focus only in a couple of methods I find more important to be aware of. This also means that I won’t spend time explaining what each operation is, just how to compute it with NumPy.
Basic vector operations
x, y = np.arange(3), np.arange(4,7)
alpha, beta = 2, 3
print(f"Vector x: {x}, vector y: {y}\n")
print(f"Vector addition: {x + y}\n")
print(f"Vector scalar-multiplication: {x * alpha}\n")
print(f"Linear combinations of vectors: {x*alpha + y*beta}\n")
print(f"Vector-vector multiplication: dot product: {x @ y}\n")
Vector x: [0 1 2], vector y: [4 5 6]
Vector addition: [4 6 8]
Vector scalar-multiplication: [0 2 4]
Linear combinations of vectors: [12 17 22]
Vector-vector multiplication: dot product: 17
Basic matrix operations
A, B, C = np.arange(1, 10).reshape(3,3), np.arange(11, 20).reshape(3,3), np.random.rand(3,3)
print(f"Matrix A:\n{A}\n")
print(f"Matrix B:\n{B}\n")
print(f"Matrix-matrix addition:\n{A+B}\n")
print(f"Matrix-scalar multiplication:\n{A*alpha}\n")
print(f"Matrix-vector multiplication: dot product:\n{A @ x}\n")
print(f"Matrix-matrix multiplication: dot product:\n{A @ B}\n")
print(f"Matrix inverse:\n{np.linalg.inv(C)}\n")
print(f"Matrix transpose:\n{A.T}\n")
print(f"Hadamard product: \n{A * B}")
Matrix A:
[[1 2 3]
[4 5 6]
[7 8 9]]
Matrix B:
[[11 12 13]
[14 15 16]
[17 18 19]]
Matrix-matrix addition:
[[12 14 16]
[18 20 22]
[24 26 28]]
Matrix-scalar multiplication:
[[ 2 4 6]
[ 8 10 12]
[14 16 18]]
Matrix-vector multiplication: dot product:
[ 8 17 26]
Matrix-matrix multiplication: dot product:
[[ 90 96 102]
[216 231 246]
[342 366 390]]
Matrix inverse:
[[-21.32169045 -3.8131569 38.56457317]
[ 4.50732439 3.31820901 -12.24388988]
[ 7.14926296 -0.18735867 -8.81170042]]
Matrix transpose:
[[1 4 7]
[2 5 8]
[3 6 9]]
Hadamard product:
[[ 11 24 39]
[ 56 75 96]
[119 144 171]]
Eigendecomposition
eigen_values, eigen_vectors = np.linalg.eig(C)
print(f"Matrix eigenvalues:\n{eigen_values}\n\nMatrix eigenvectors:\n{eigen_vectors}")
Matrix eigenvalues:
[ 1.68949164 -0.03099435 0.20589414]
Matrix eigenvectors:
[[-0.49129322 -0.93332275 0.55829177]
[-0.79415823 0.21672628 -0.77249178]
[-0.35769216 0.28624879 0.30259999]]
Singular value decomposition
U, S, T = np.linalg.svd(C)
print(f'Left orthogonal matrix C:\n{np.round(U, 2)}\n')
print(f'Singular values diagonal matrix C:\n{np.round(S, 2)}\n')
print(f'Right orthogonal matrix C:\n{np.round(T, 2)}')
Left orthogonal matrix C:
[[-0.54 -0.69 0.48]
[-0.75 0.65 0.09]
[-0.38 -0.31 -0.87]]
Singular values diagonal matrix C:
[1.89 0.27 0.02]
Right orthogonal matrix C:
[[-0.36 -0.57 -0.74]
[ 0.07 0.77 -0.63]
[-0.93 0.28 0.23]]
Strings operations with NumPy
Turns out NumPy is not only a power number-crunching engine but also pretty good at handling strings. Although strings (letters, characters) and numbers are completely different things from a human perspective, both reduce to sequences of zeros and ones to the computer, so NumPy can work with strings in a vectorized fashion as well.
Basic string manipulation
String manipulation is a whole area of expertise in itself, so we can’t and won’t dig very deep into it. Yet, NumPy can help you out to perform a wide variety of common string operations with relative ease. Let’s check a few.
string1 = np.array(["Ms", "Mx", "Mr", "Dr", "Lord"])
string2 = np.array(["Weird", "Smelly", "Smart", "Strong", "Happy"])
string3 = np.array([" pants ", " feet ", " belly buttom ", " elbow ", " jaw "])
print(f"Add strings:\n{np.char.add(string1, string2)}\n")
print(f"Multiply strings:\n{np.char.multiply(string1, 2)}\n")
print(f"Capitalize first letter of strings:\n{np.char.capitalize(string3)}\n")
print(f"Join strings in a sequence:\n{np.char.join('-', string1)}\n")
print(f"Replace string elements:\n{np.char.replace(string2, 'S', 'P')}\n")
print(f"Strip char elements from the beginning and end of the string (useful to remove white spaces):\n{np.char.strip(string3, chars=' ')}\n")
print(f"Title case strings:\n{np.char.title(string3)}\n")
print(f"Upper case strings:\n{np.char.upper(string3)}\n")
Add strings:
['MsWeird' 'MxSmelly' 'MrSmart' 'DrStrong' 'LordHappy']
Multiply strings:
['MsMs' 'MxMx' 'MrMr' 'DrDr' 'LordLord']
Capitalize first letter of strings:
[' pants ' ' feet ' ' belly buttom ' ' elbow ' ' jaw ']
Join strings in a sequence:
['M-s' 'M-x' 'M-r' 'D-r' 'L-o-r-d']
Replace string elements:
['Weird' 'Pmelly' 'Pmart' 'Ptrong' 'Happy']
Strip char elements from the beginning and end of the string (useful to remove white spaces):
['pants' 'feet' 'belly buttom' 'elbow' 'jaw']
Title case strings:
[' Pants ' ' Feet ' ' Belly Buttom ' ' Elbow ' ' Jaw ']
Upper case strings:
[' PANTS ' ' FEET ' ' BELLY BUTTOM ' ' ELBOW ' ' JAW ']
Basic string comparison
String comparison in NumPy utilizes the same logic as with numbers. Keep in mind you have to use the methods from the char module. Be aware that white spaces at the end of the string will be removed before comparison.
strings = np.array(["cat", "dog", "dog ", "lizard"])
print(f"Equality comparison cat-dog: {np.char.equal(strings[0],strings[1])}")
print(f"Equality comparison dog-dog: {np.char.equal(strings[1],strings[2])}\n")
print(f"Inequality comparison cat-dog: {np.char.not_equal(strings[0],strings[1])}")
print(f"Inequality comparison dog-dog: {np.char.not_equal(strings[1],strings[2])}\n")
print(f"Greather than comparison cat-lizard: {np.char.greater(strings[0],strings[3])}")
print(f"Less than comparison lizard-dog: {np.char.not_equal(strings[3],strings[2])}\n")
Equality comparison cat-dog: False
Equality comparison dog-dog: True
Inequality comparison cat-dog: True
Inequality comparison dog-dog: False
Greather than comparison cat-lizard: False
Less than comparison lizard-dog: True
String information
There are many instances where you will want to search for or information contained in a string. NumPy also has a rich list of methods to approach that:
strings2 = np.array(["Psychotomimetic", "Trichotillomania",
"Omphaloskepsis","Xenotransplantation",
"Embourgeoisement", "Polyphiloprogenitive",
"12345", " "])
print(f"Count number of times substring 'p' occurs in string: {np.char.count(strings2, 'p')}\n")
print(f"Check whether the strings ends with 's': {np.char.endswith(strings2, 's')}\n")
print(f"Find the first ocurrence 's' and return the index postion: {np.char.find(strings2, 's')}\n")
print(f"Find strings with numeric characters only: {np.char.isnumeric(strings2)}\n")
print(f"Find strings with at least one white space: {np.char.isspace(strings2)}\n")
Count number of times substring 'p' occurs in string: [0 0 2 1 0 2 0 0]
Check whether the strings ends with 's': [False False True False False False False False]
Find the first ocurrence 's' and return the index postion: [ 1 -1 7 8 10 -1 -1 -1]
Find strings with numeric characters only: [False False False False False False True False]
Find strings with at least one white space: [False False False False False False False True]